使用帮助
校对流程:四层级精校体系,从行到字全覆盖
云聪古籍平台提供业界领先的数字化校对系统,支持行级校对、字符校对、区块校对、覆盖检查四种层级,配合全程快捷键操作和集字校对功能,满足从粗校到出版级精校的全流程需求。平台校编团队30余人,已为80多所高校提供服务,积累了丰富的古籍校对经验。
一、四种校对级别
平台根据不同的校对需求,设计了四种校对级别,可在顶部工具栏一键切换:
1、行级校对(行级)
行级校对是最常用的校对模式。系统将竖版繁体文字转换为横版排列,识别结果逐行展示。您可以在图像画布上查看每行文字的区块位置,点击行块即可在右侧文本列表中高亮对应行。支持全程快捷键键盘操作,符合现代阅读习惯,校对效率极高。
操作方式:在图像上点击行块选中该行,右侧文本区同步定位;在文本区双击行可进入编辑状态,直接修改文字内容。

2、字符校对(字符)
进入字符模式后,图像上每个文字都标记为独立的可点击区域。点击单个字符,右侧显示该字的候选替换列表(同音字、形似字),支持Alt+数字键或鼠标点击快速替换。适合对识别准确率要求极高的出版级校对场景。
字符模式下,每个文字的边界框在图像上清晰可见,校对人员可以逐字比对原文图像与识别结果,不错过任何一个错误。

3、区块校对(区块)
区块模式用于版面布局的调整。古籍的版面往往复杂多样——筒子页、半筒子页、上下栏、批注栏等,OCR识别后的区块位置可能不够精准。在区块模式下,您可以拖动区块边界调整位置和大小,删除多余区块或新增区块,重新识别后获得更精准的文字排列。
对于族谱、家谱、县志等包含复杂表格和分栏的文献,区块校对是保证阅读顺序正确的前提。
4、覆盖检查(覆盖)
覆盖检查是平台新增的强力校对功能。在覆盖模式下,系统将OCR识别文字的边界框叠加显示在古籍原图上,每个文字框与原始图像上的文字一一对应。您可以通过视觉对比,快速发现识别错误或遗漏的文字。
覆盖检查特别适合手写体、污损版面的古籍校对——当常规逐字校对难以发现细微错误时,覆盖模式下的图文叠加让问题一目了然。

二、逐字校对快捷键
云聪古籍的逐字校对系统提供了完整的键盘快捷键操作,熟练使用后可大幅提升校对效率:
| 快捷键 | 功能说明 |
|---|---|
| ESC键 | 光标返回到逐字精校区 |
| ← → 左右箭头 | 选中前、后一个字 |
| ↑ ↓ 上下箭头 | 选中上、下一行 |
| HOME键 | 选中当前行第一个字 |
| END键 | 选中当前行最后一个字 |
| Ctrl + S | 保存当前页校对结果 |
| Ctrl + → | 保存校对结果并跳转到下一页 |
| Ctrl + ← | 保存校对结果并跳转到上一页 |
| Ctrl + ↑ | 上移当前行(调整语序) |
| Ctrl + ↓ | 下移当前行(调整语序) |
| Enter回车键 | 查询当前选中字的同音字和形似字 |
| Alt + 数字键 | 用候选列表中第N个字替换当前选中字 |
三、集字校对
集字校对是提升校对效率的利器。针对多本古籍或某个项目的识别结果,系统通过大数据统计,将相同的文字对应的图像集合在一起统一展示。
比如"曰"字,在一批古籍中出现了上千次,系统将这上千个"曰"的图像集中排列。其中大部分是识别正确的,只有少数是识别错误的。正确与错误放在一起对比,错误之处一目了然,无需逐页翻查。
集字校对大大减轻了校对人员的视觉负担,避免陷入繁琐的上下文判断。适用于批量古籍的快速精校场景,可在短时间内将识别准确率提升至99%以上。
集字校对仅对企业会员开放。

四、三校法(推荐流程)
基于多年的古籍校对经验,平台推荐"三校法"工作流程:
一校:行级粗校——使用行级校对模式,逐行通读文本,确保文字对齐、行序正确。此阶段可达到95%以上的正确率。
二校:集字精校——使用集字校对功能,对高频错字集中纠错。系统将相同文字的图像集中排列,错误识别一目了然。此阶段可达到99%的正确率。
三校:覆盖终校——使用覆盖检查模式,对二校标记的可疑文字所在页面进行最终确认。图文叠加对比,确保不遗漏任何错误。三校后正确率可达99.8%以上,满足出版及国家标准要求。
对于版面规范、文字规整的古籍,可以适当简化流程;对于图像质量较差、手写体较多的古籍,建议严格执行三校法,确保最终质量。
五、校对实例
规整版面——明清刻本、印刷体为主的古籍,版面整洁无污垢。使用方向键快速逐字校验即可,效率极高。
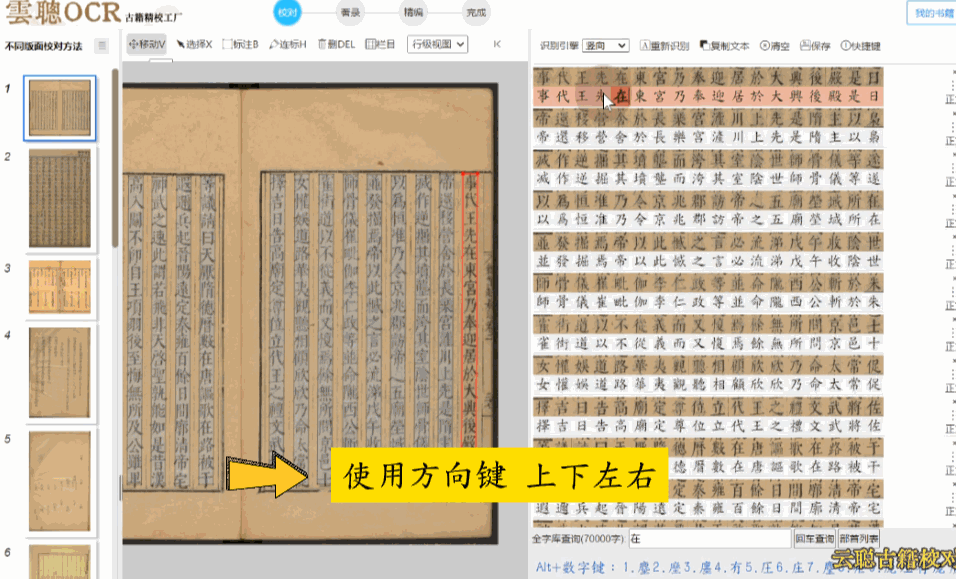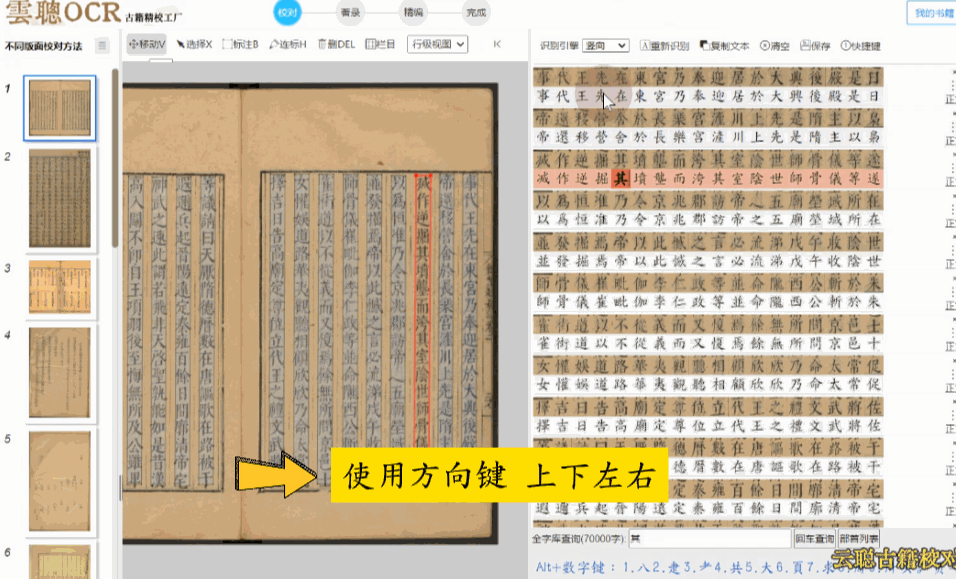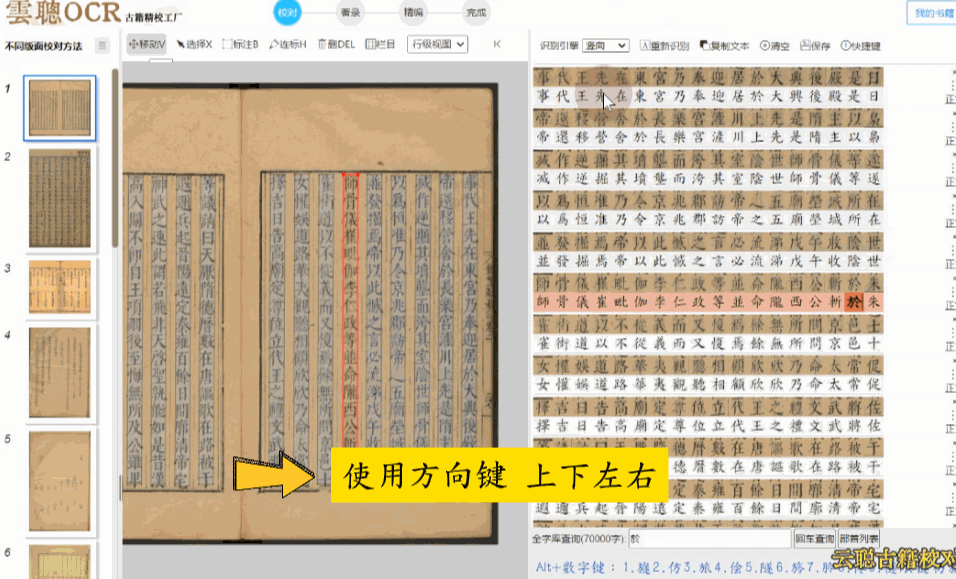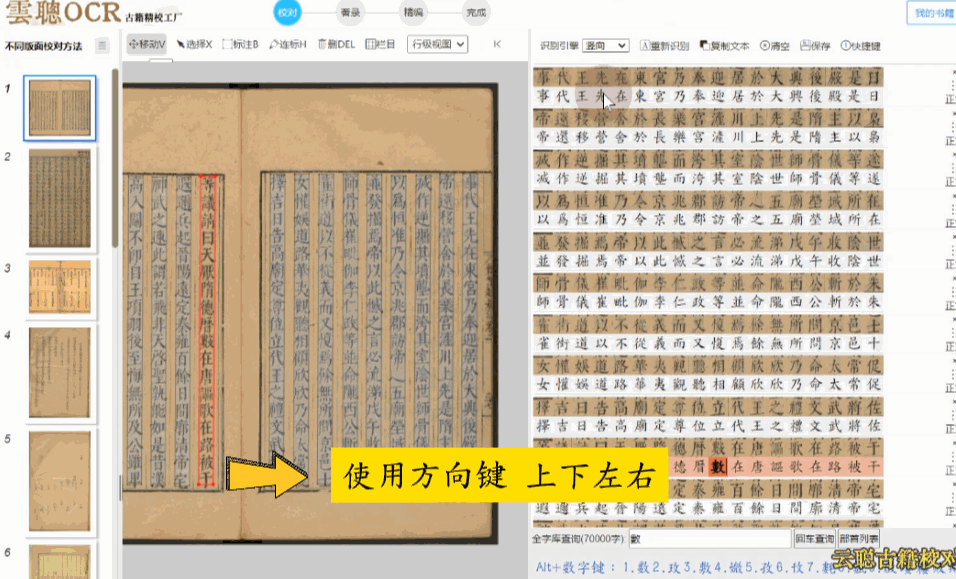
杂乱版面——注释较多、行间有圈点的古籍,可能出现文本区块多标、位置偏移。建议先进入区块模式调整布局,再逐字校对。
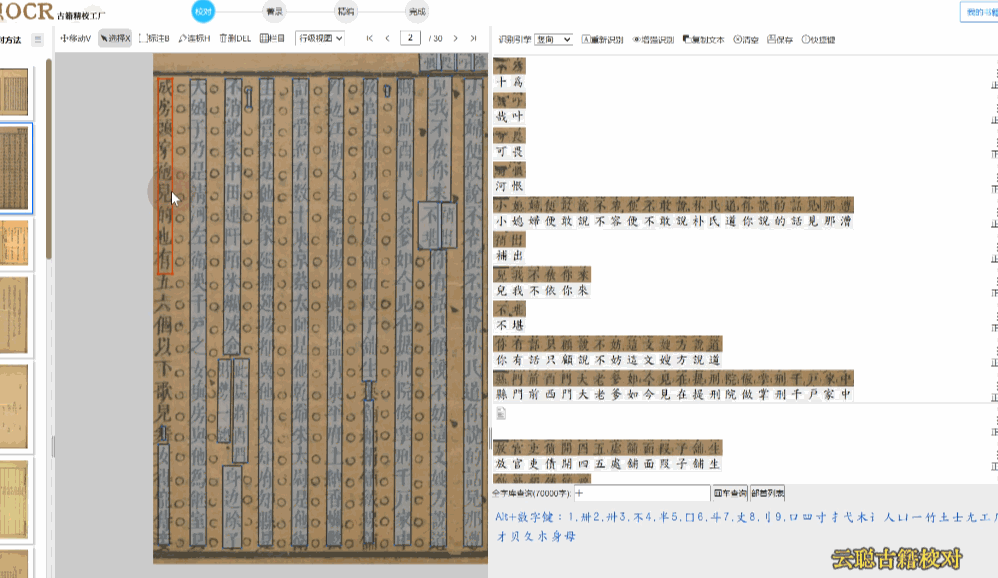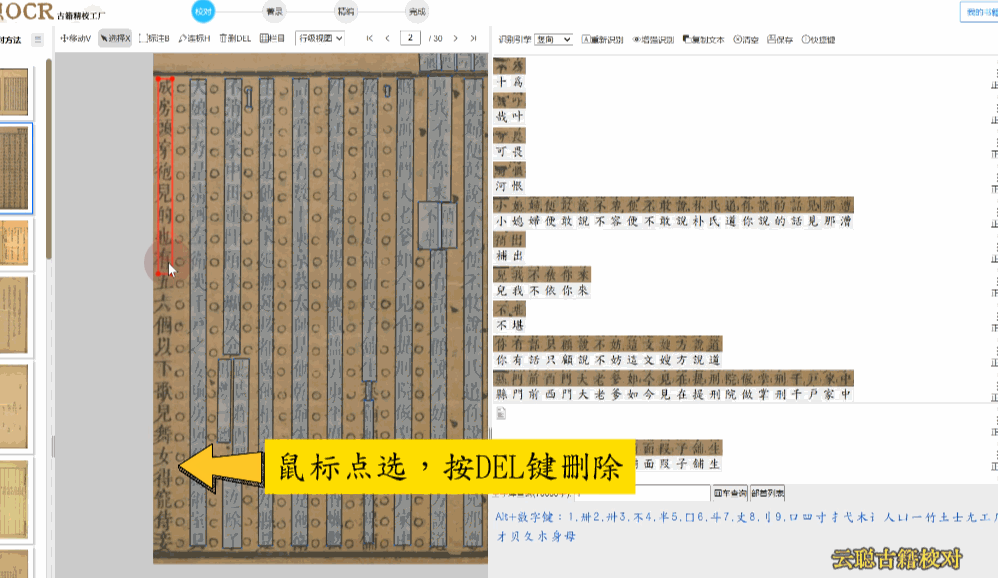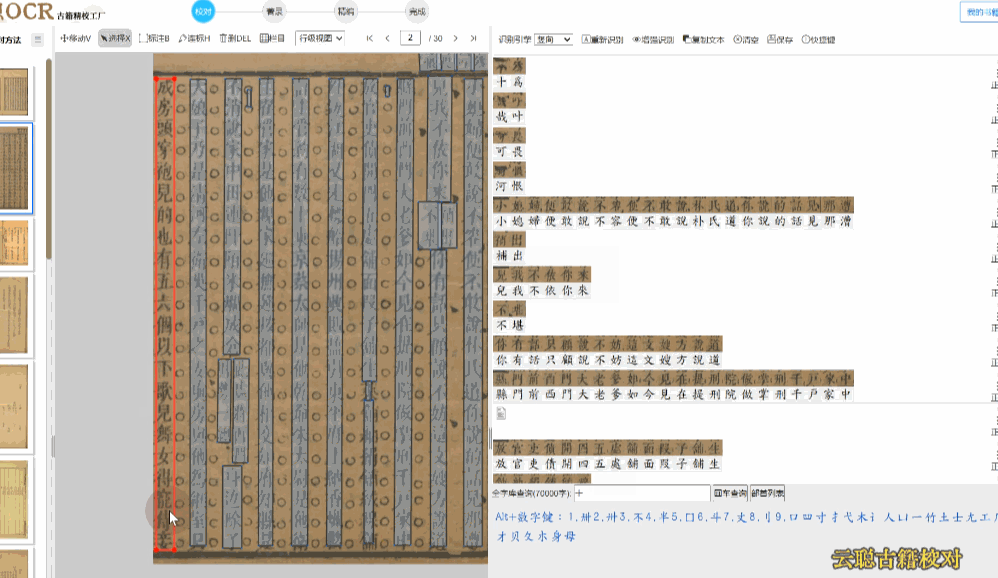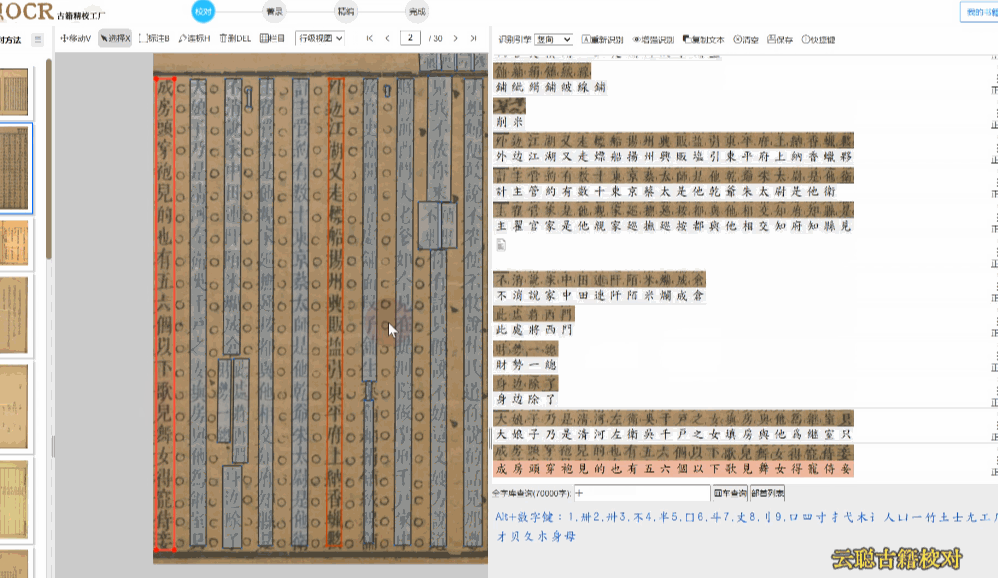
模糊版面——页面污损、透光、透字的古籍。建议使用覆盖检查模式,图文叠加对比,或使用增强识别重新OCR后再校对。
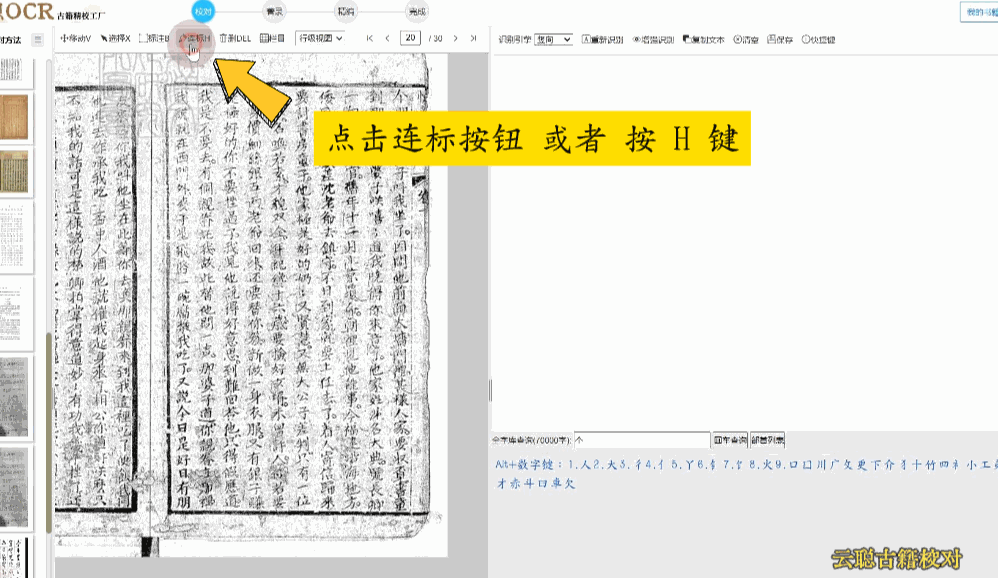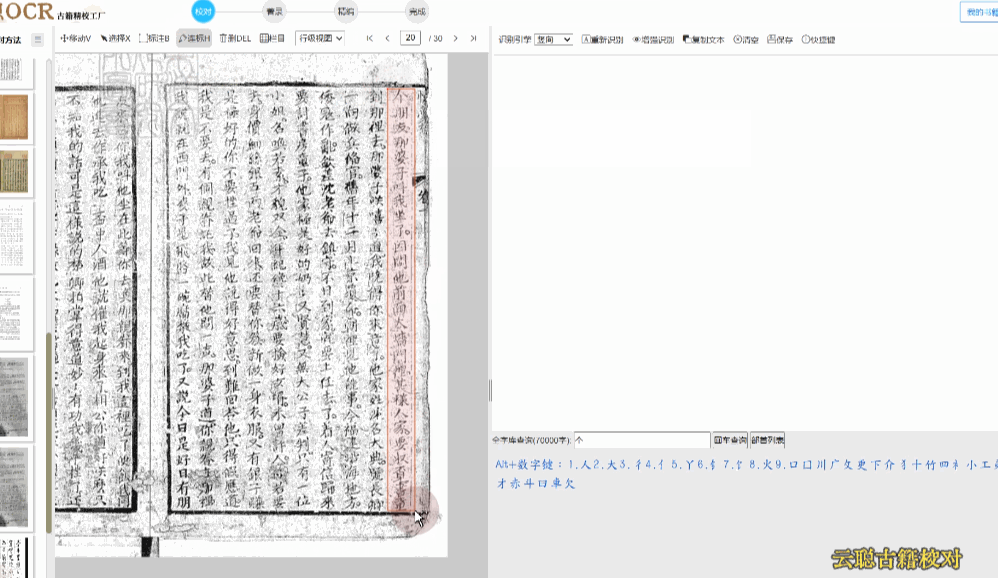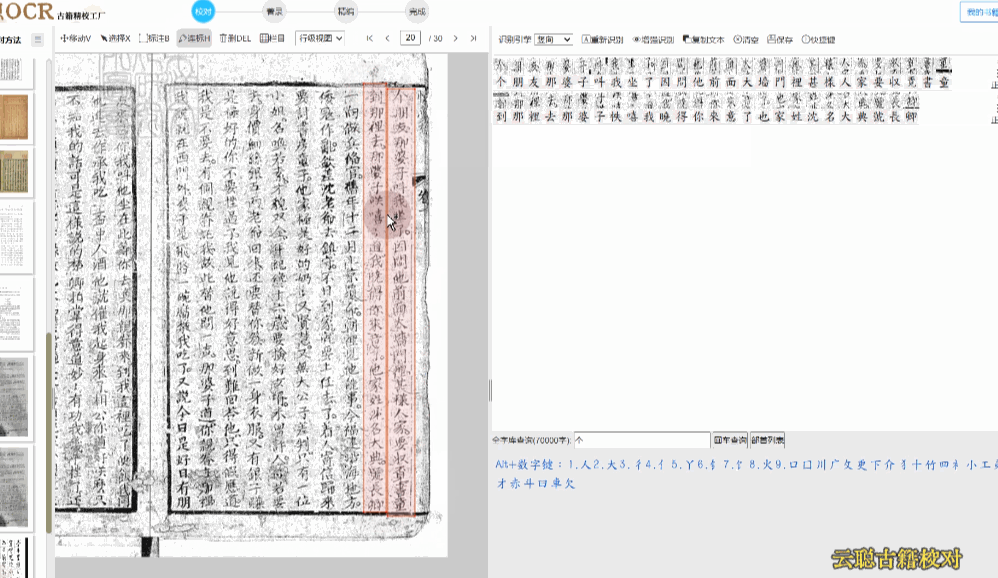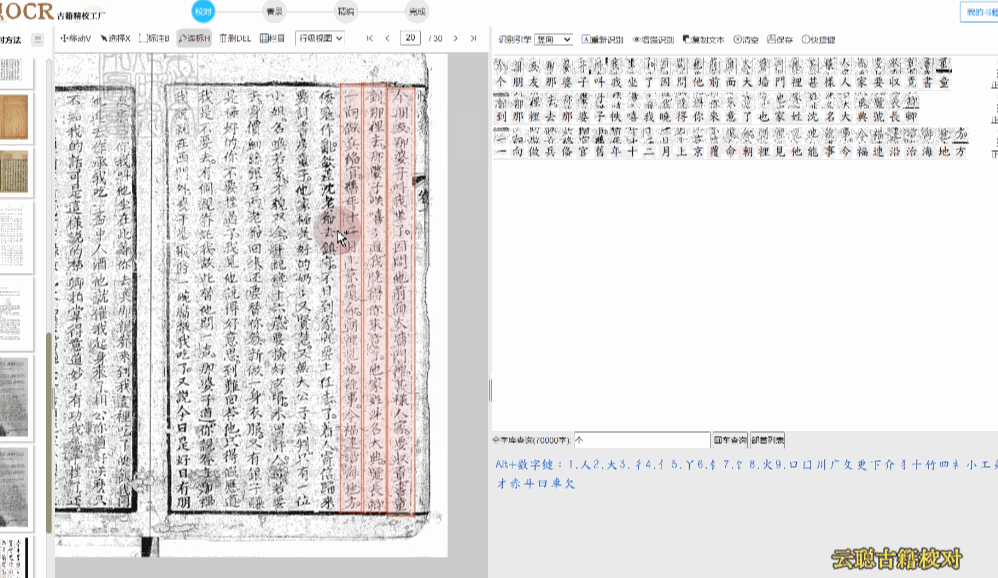
带天头地脚——天头位置有批校的古籍,建议使用区块模式将天头批校与正文分开处理。
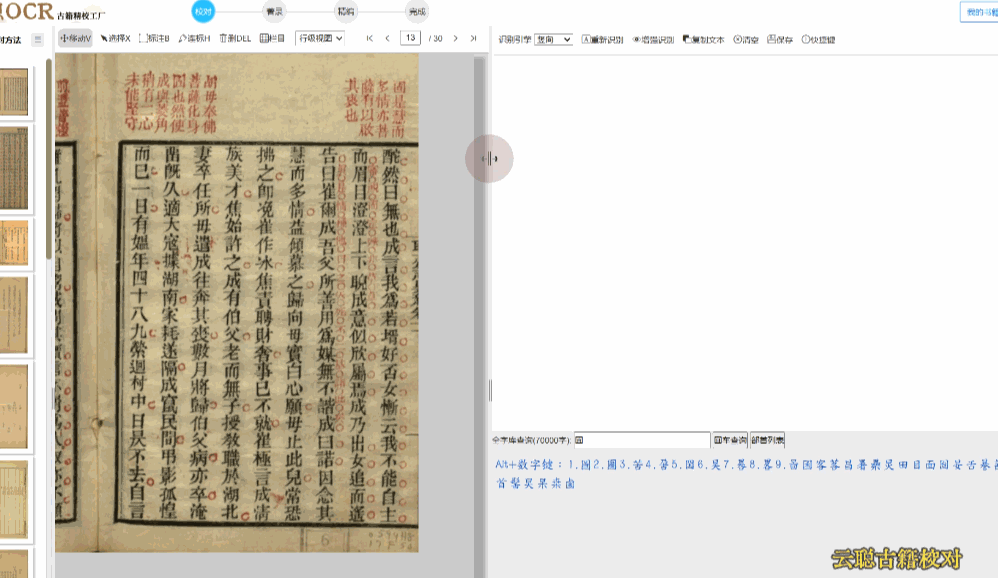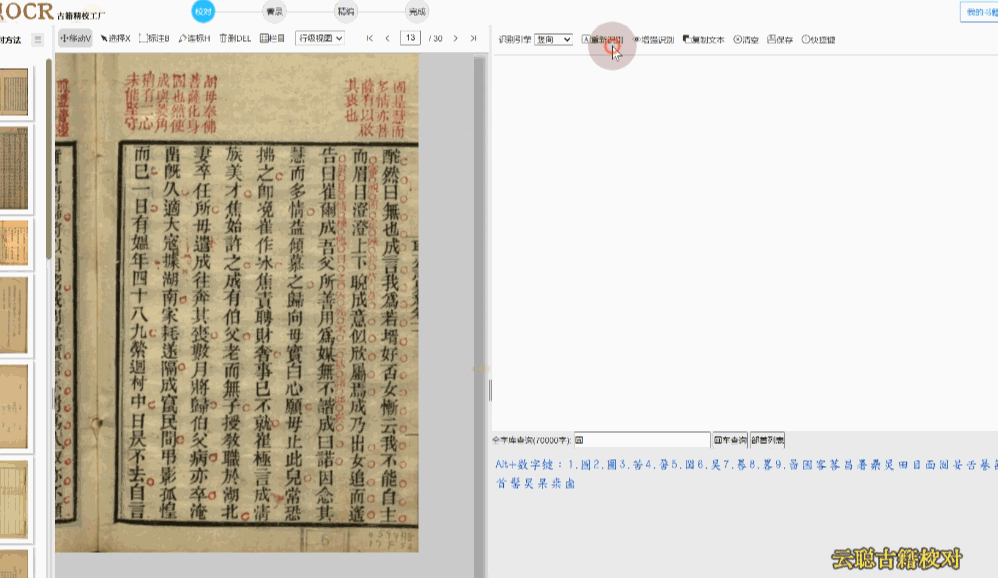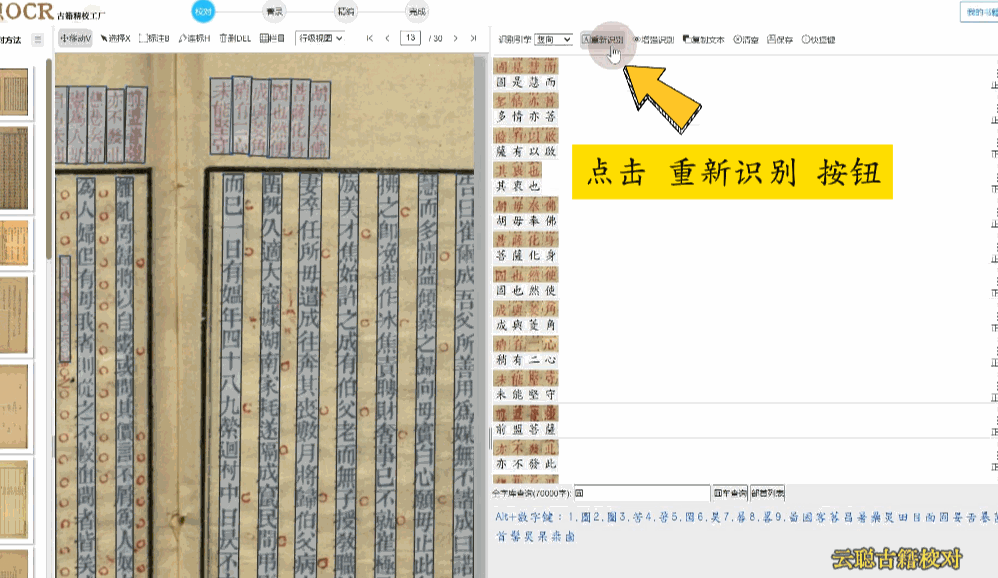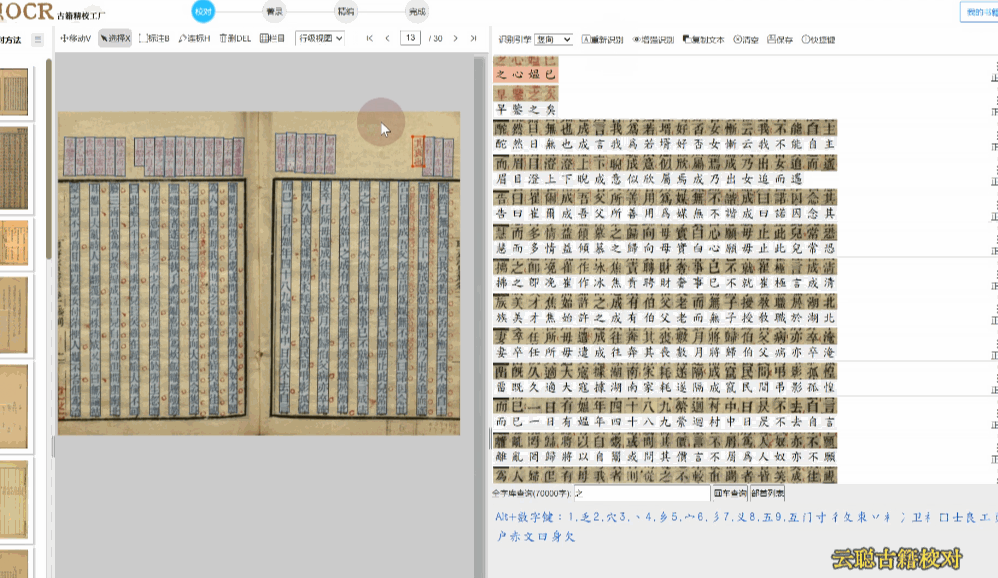
族谱版面——手写抄本居多,按辈分上下分层。建议先使用区块模式划分栏目,再逐行校对语序。
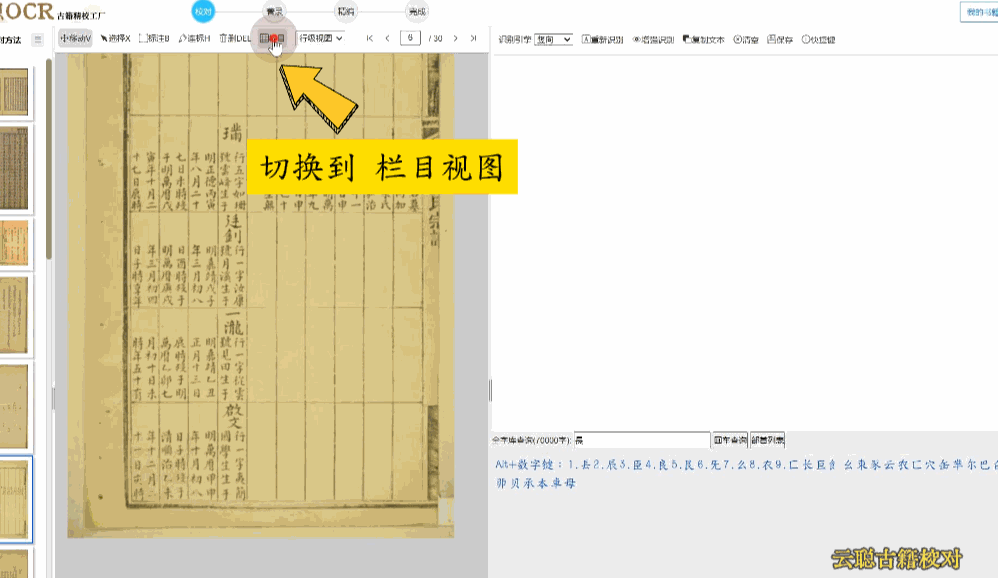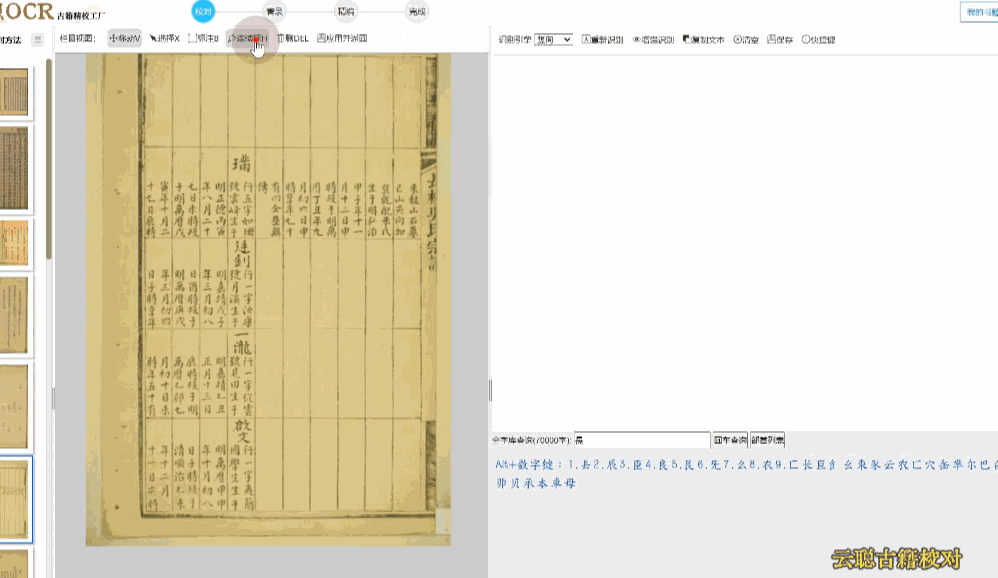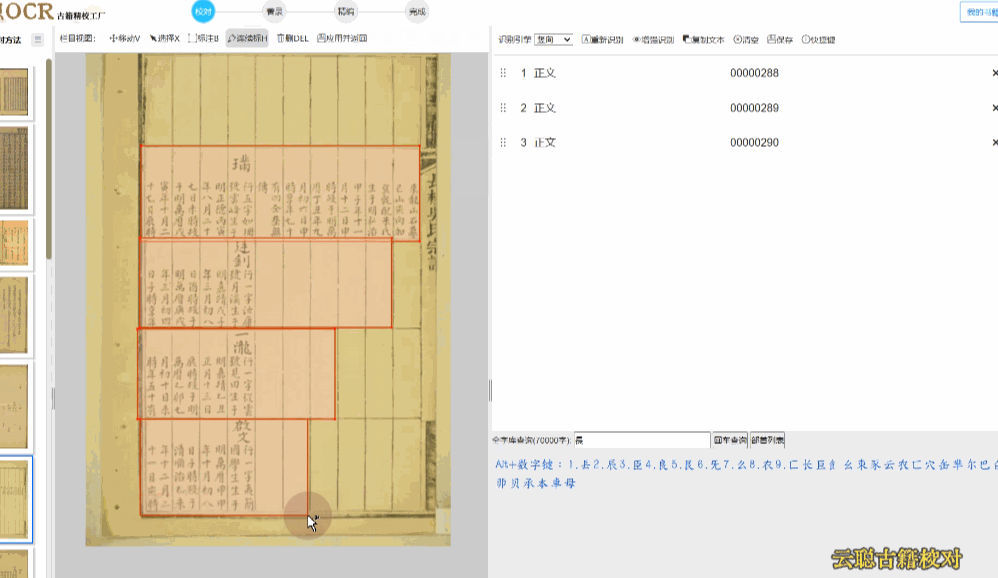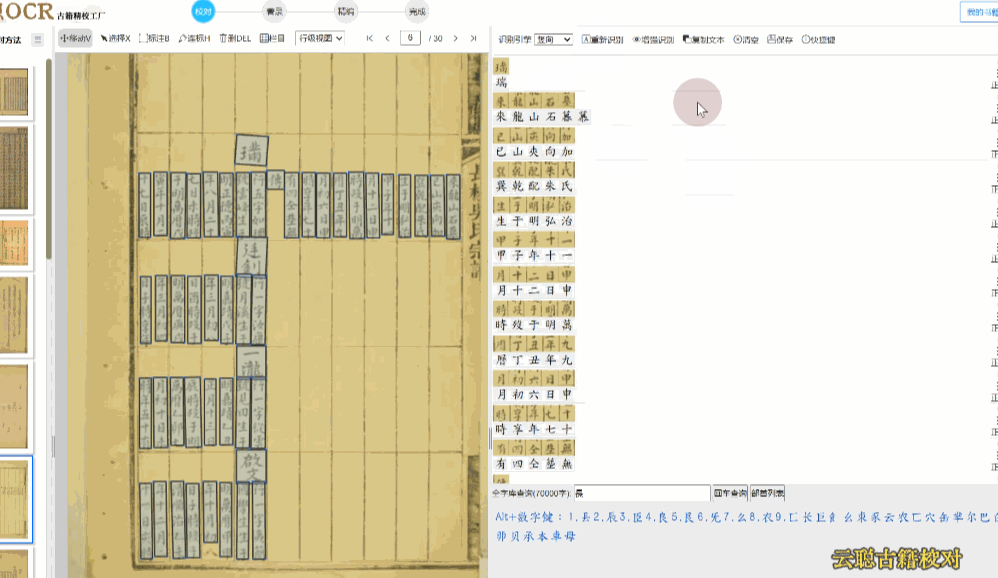
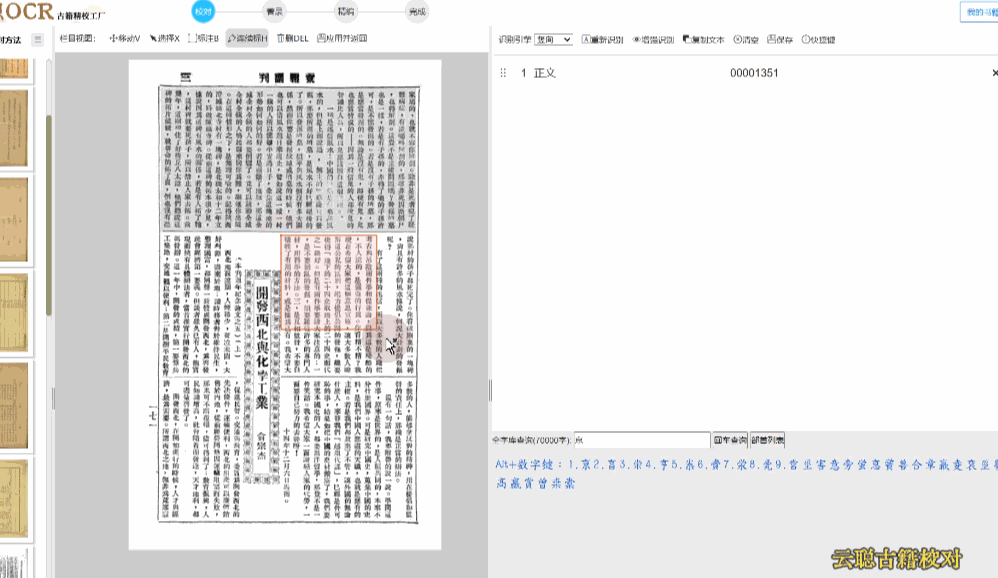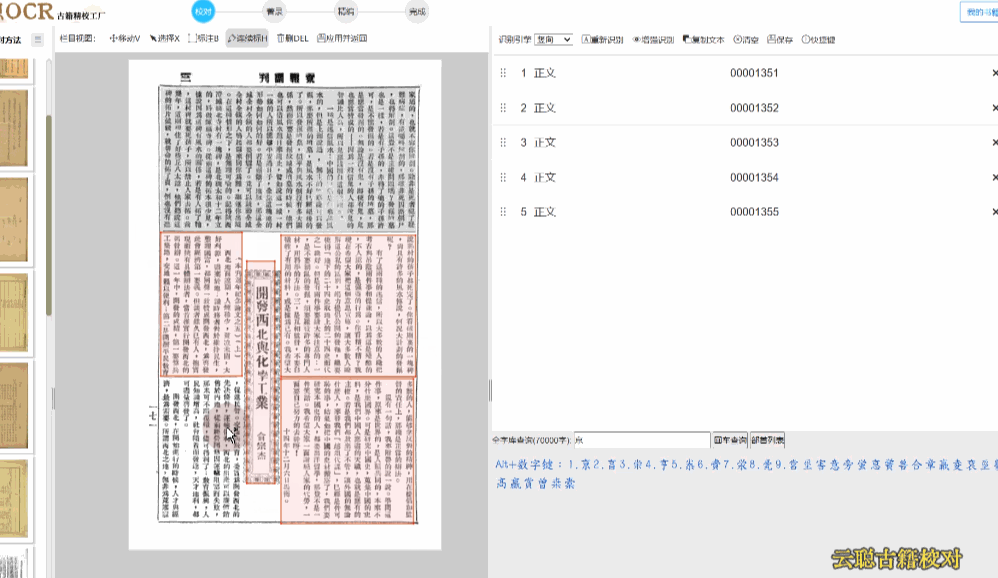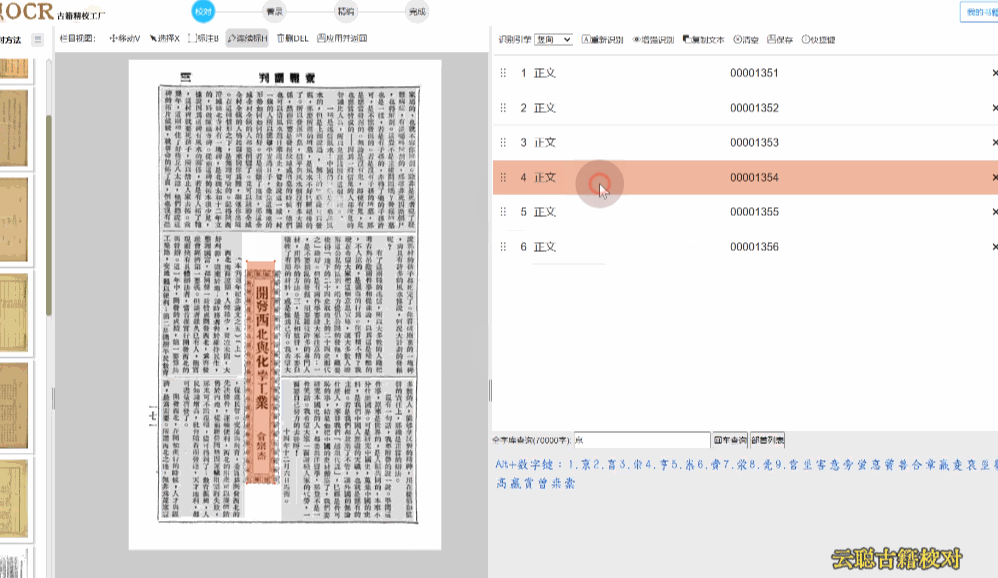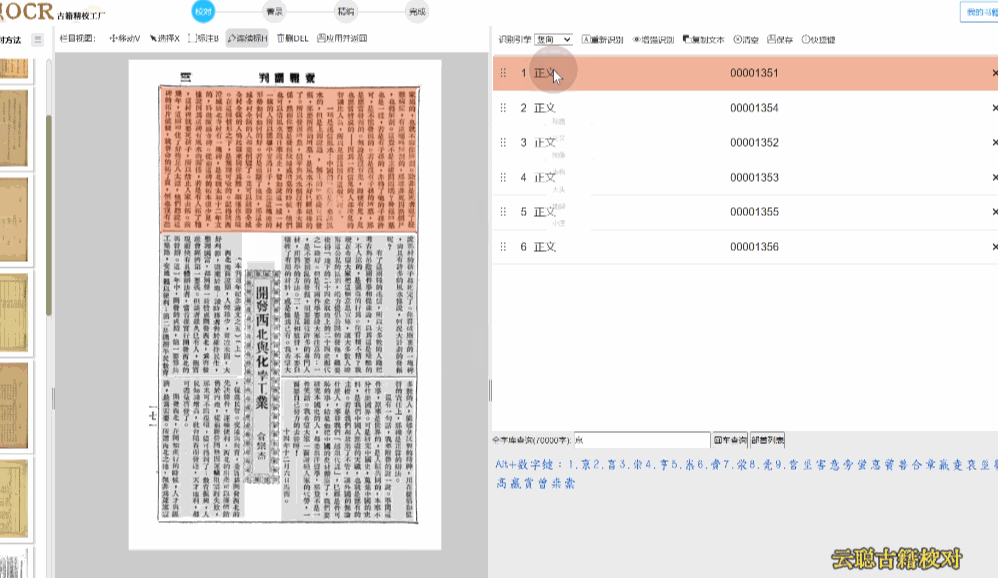
民国报刊版面
民国期刊栏目较多,默认识别的会出现语序杂乱的情况。
校对方法:切换到栏目视图,画出栏目区块再进行识别 或者 选择识别引擎为"混排",重新识别
横向繁体版面
文本方向为横向,多出现于60年代的期刊报纸。
校对方法:横向繁体注意在识别的时候,选择识别引擎为"横向"即可

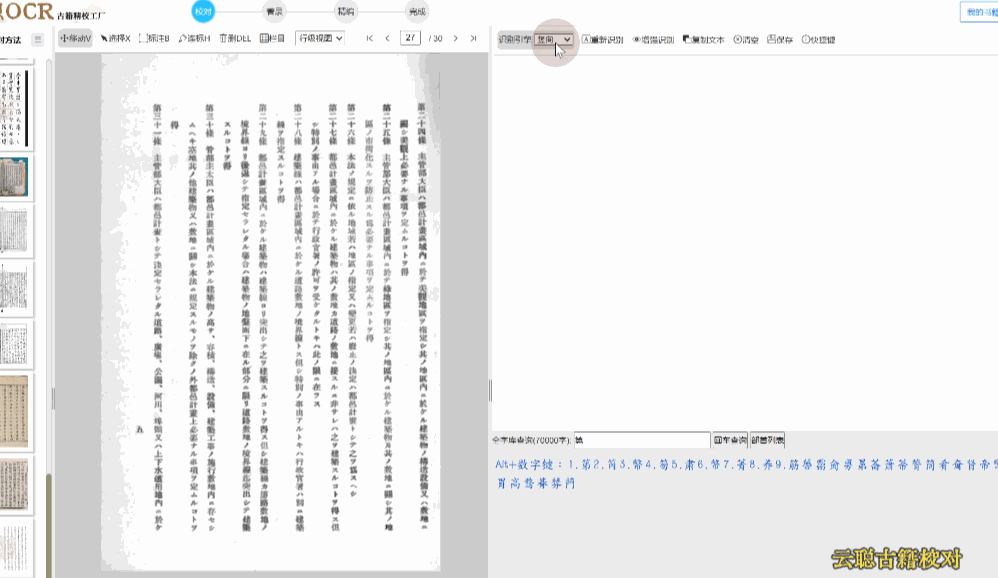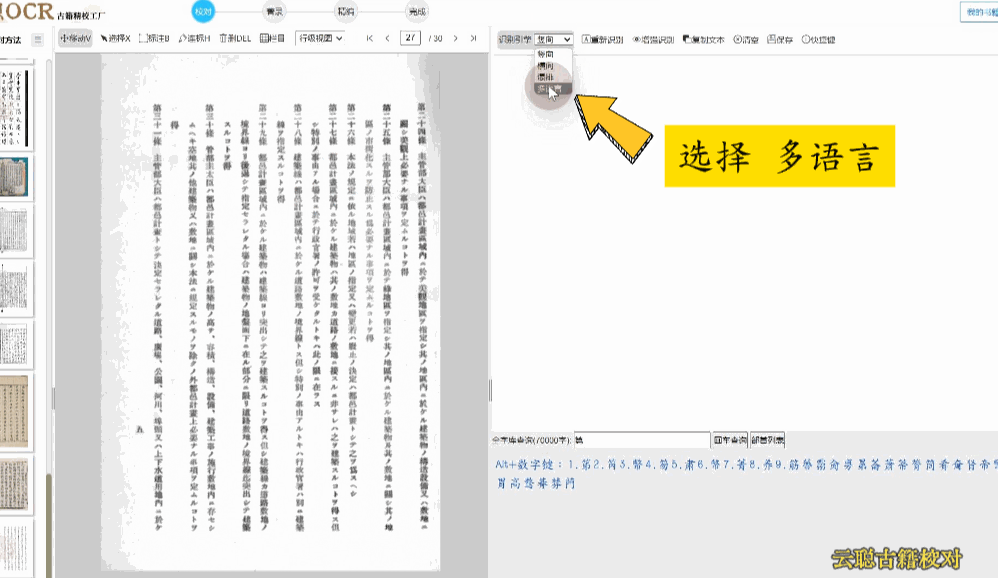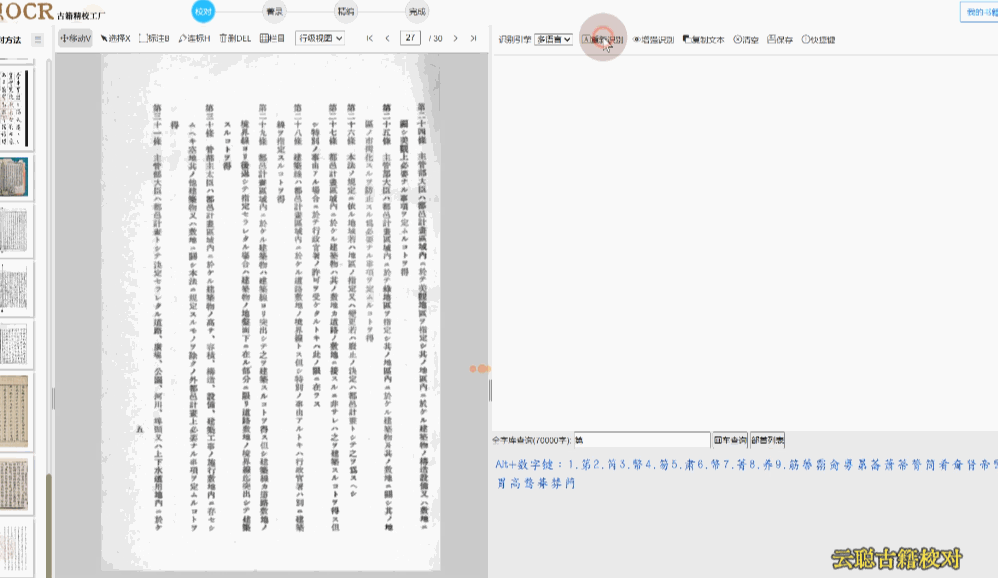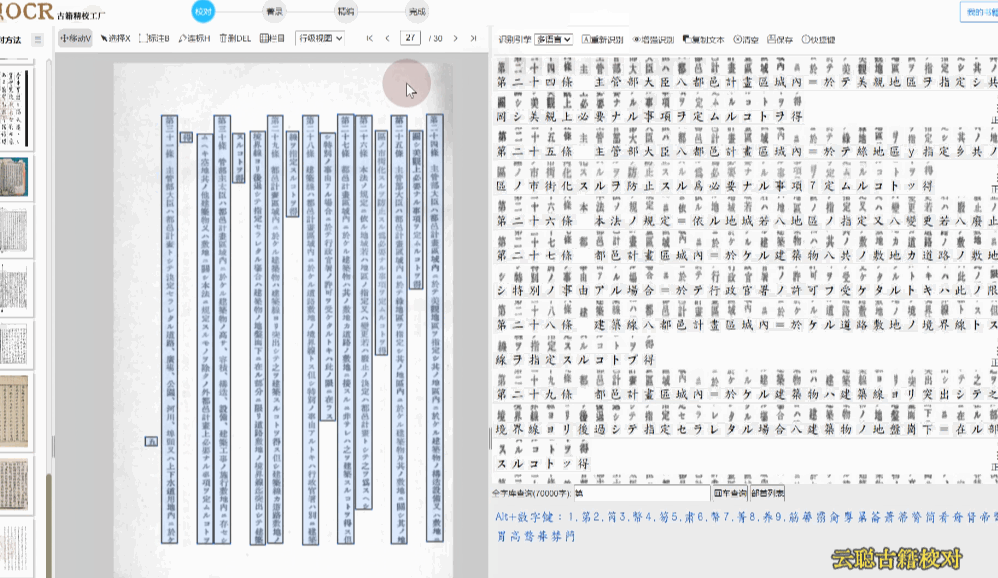
多语种版面
多语种版面就是文字中有日文、韩文、英文等字符。
校对方法:选择识别引擎为"多语言",重新识别