使用帮助
OCR识别能力:国内一线水平,精准识别古籍文字
云聪古籍OCR识别引擎由哈工程博士团队研发,历经多年技术迭代,识别能力处于国内一线水平,在历次古籍OCR技术评测中识别准确率均位居前列。平台支持8.7万个繁简汉字的OCR识别,涵盖大部分异体字,并且对手写字体也有很好的识别精度。
本模块支持私有化部署及API调用。
一、技术核心
1、识别核心
云聪OCR精校工厂内置云聪科技最新研发的高性能文字识别引擎,可识别新国标收录汉字87887个。其中《国标GB2312汉字编码字符集》常用汉字6763个,平均识别率达99.9%以上;《国标GB18030-2022中文编码字符集》常见繁体异体汉字27533个,中文汉字平均识别率达95%以上。另外多语言版本英文、日文、韩文的识别率居国内主流水平。


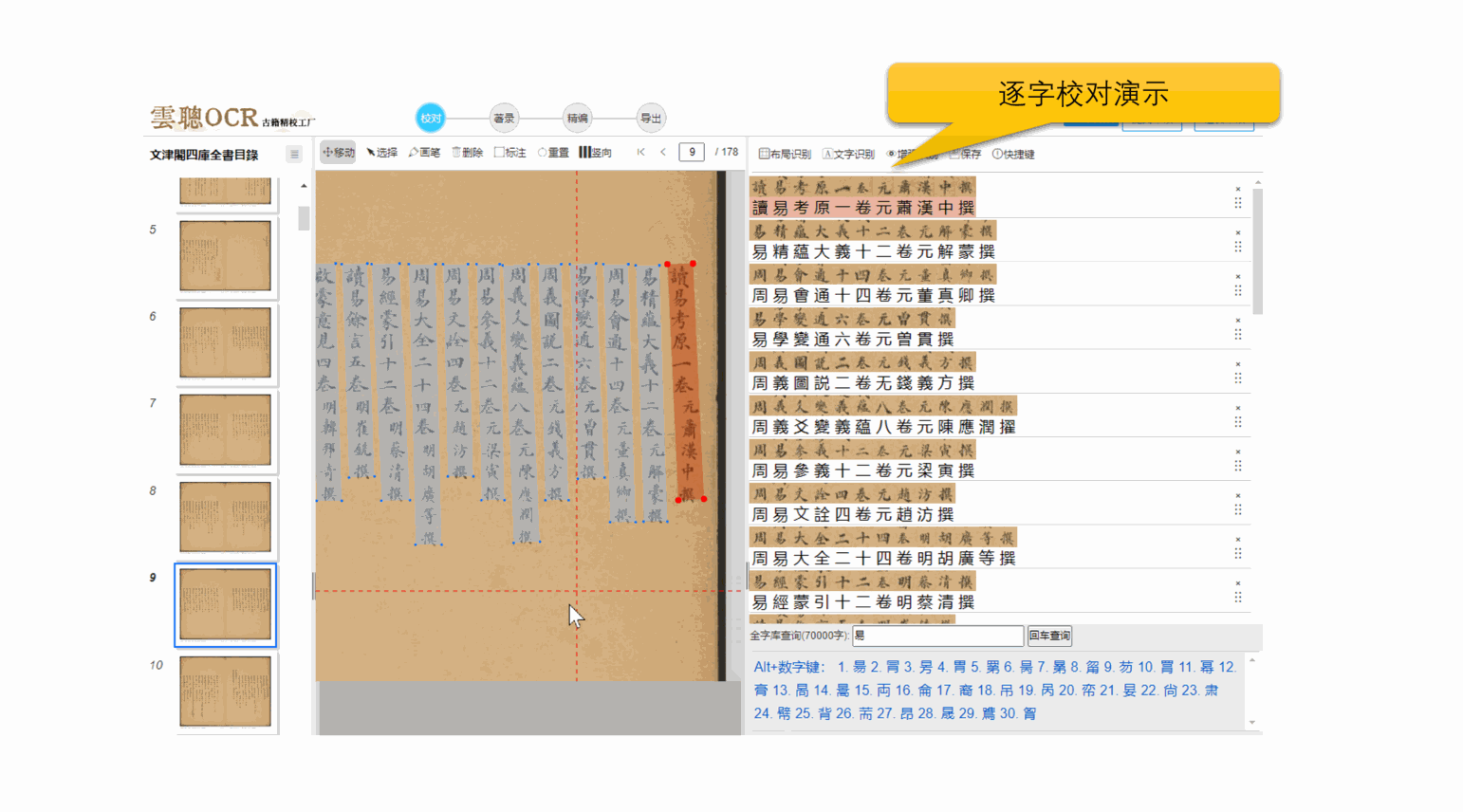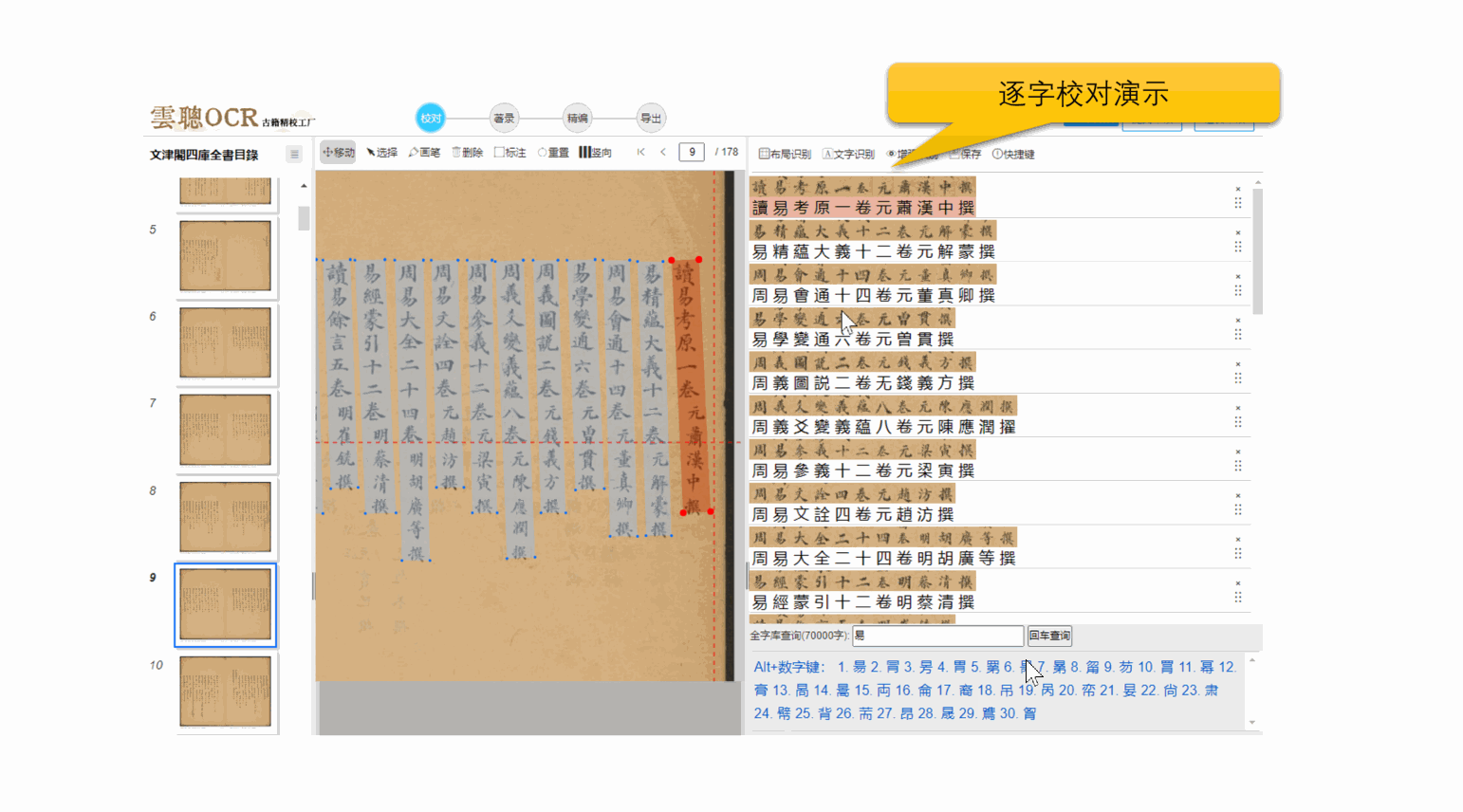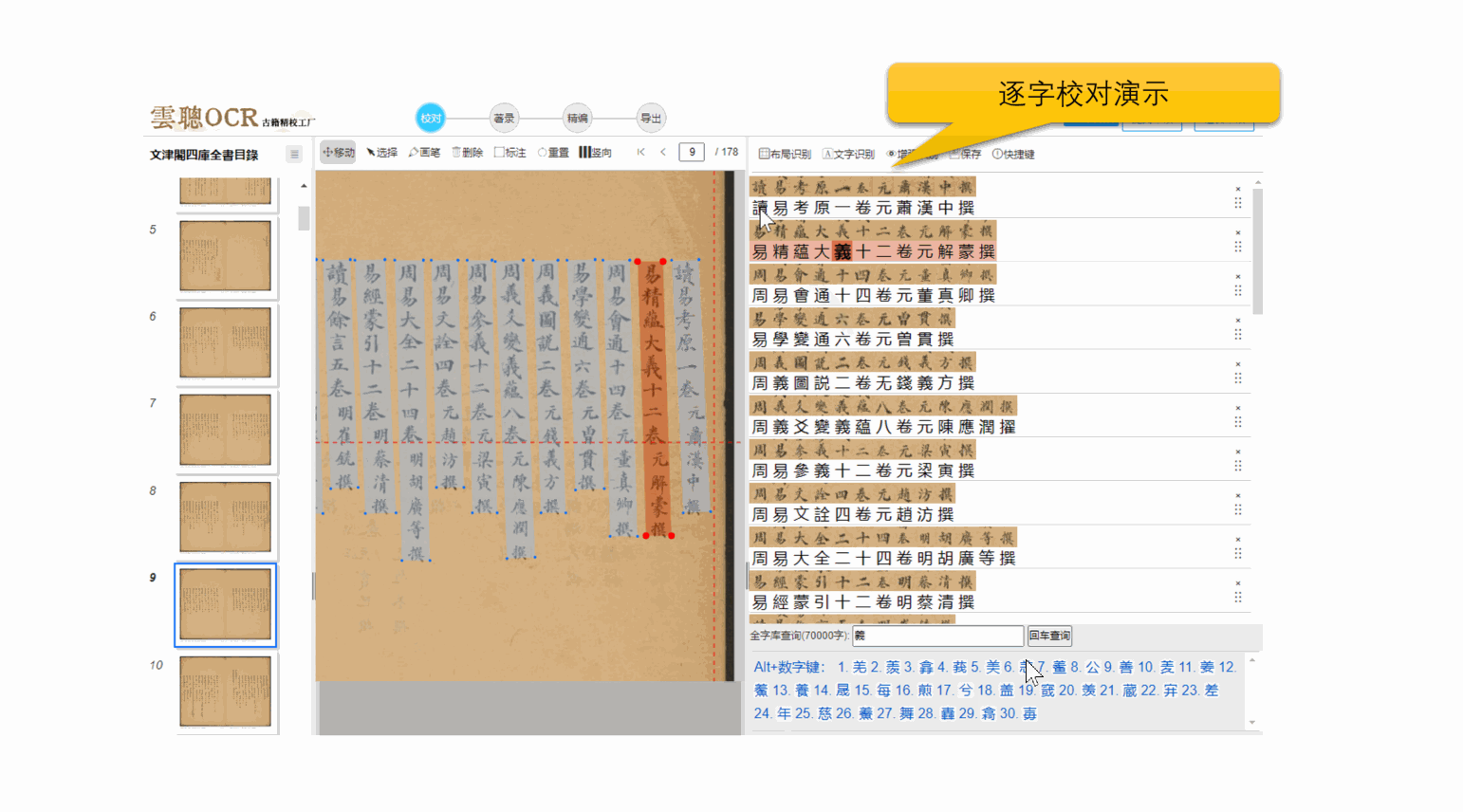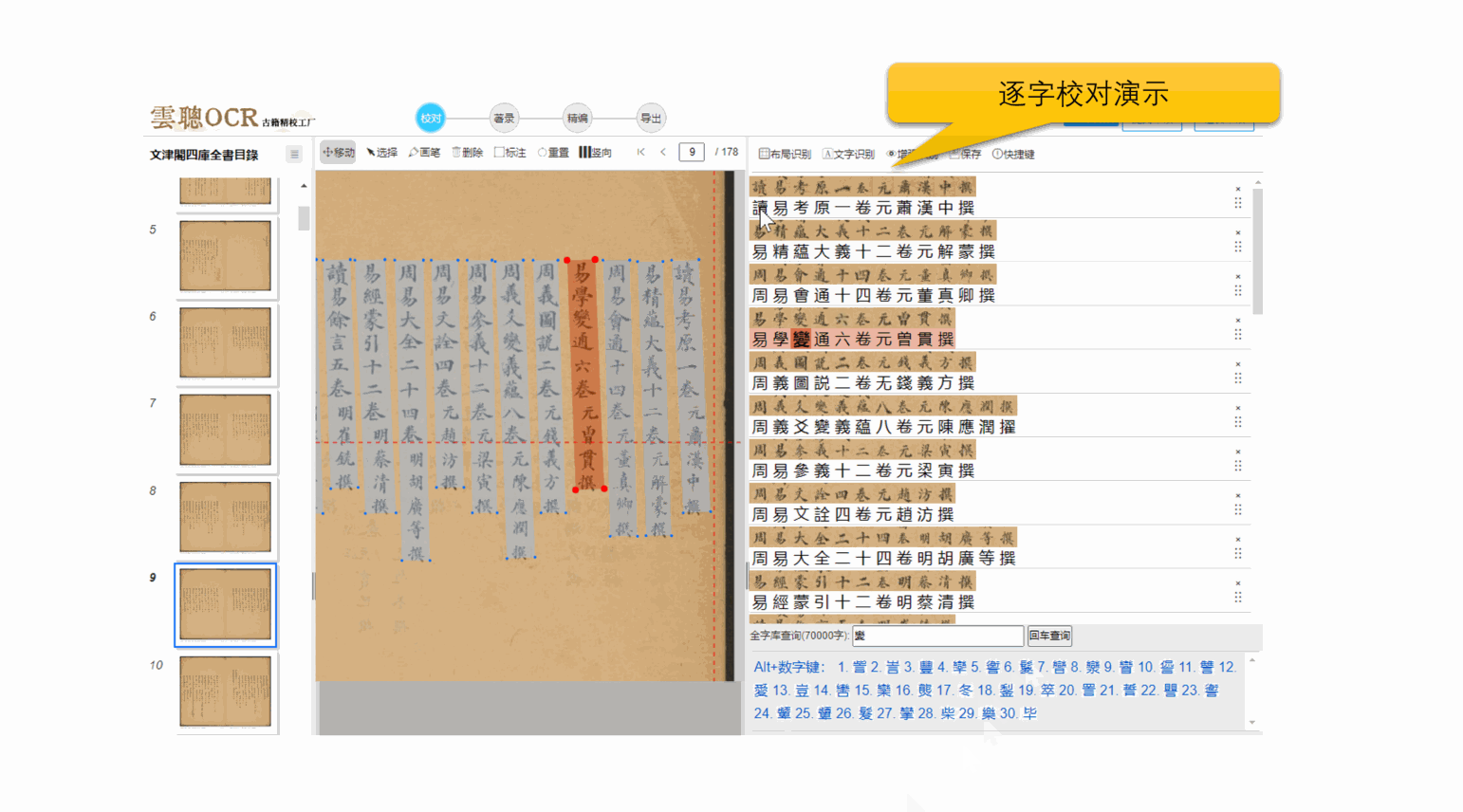
2、逐字横排校对
云聪OCR精校工厂支持将竖版繁体文字转换为横版繁体文字,单个文字上下一对一进行逐字校对,支持全程快捷键键盘操作,符合现在的阅读习惯,大大提高校对效率。
3、复杂版面分析
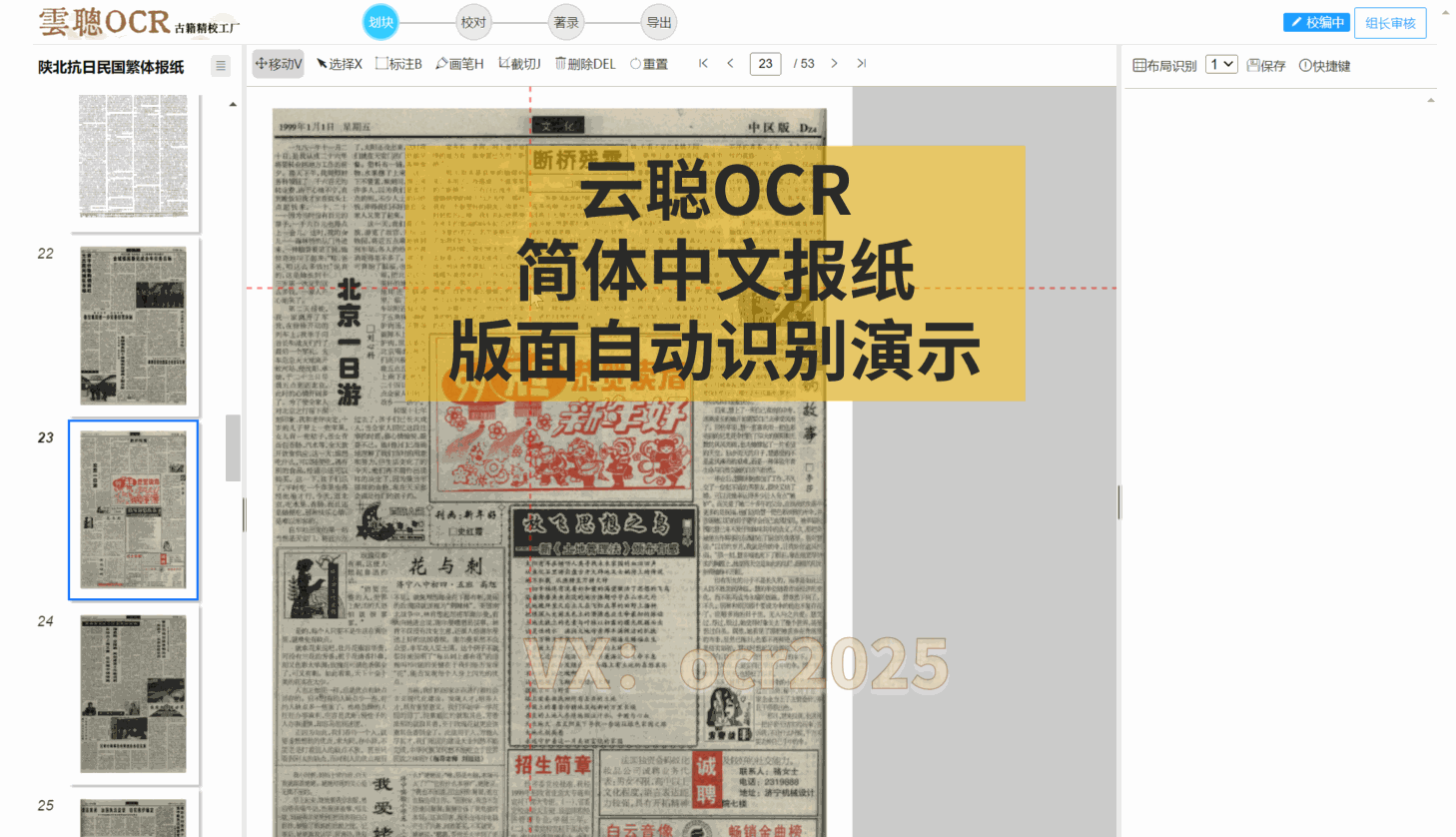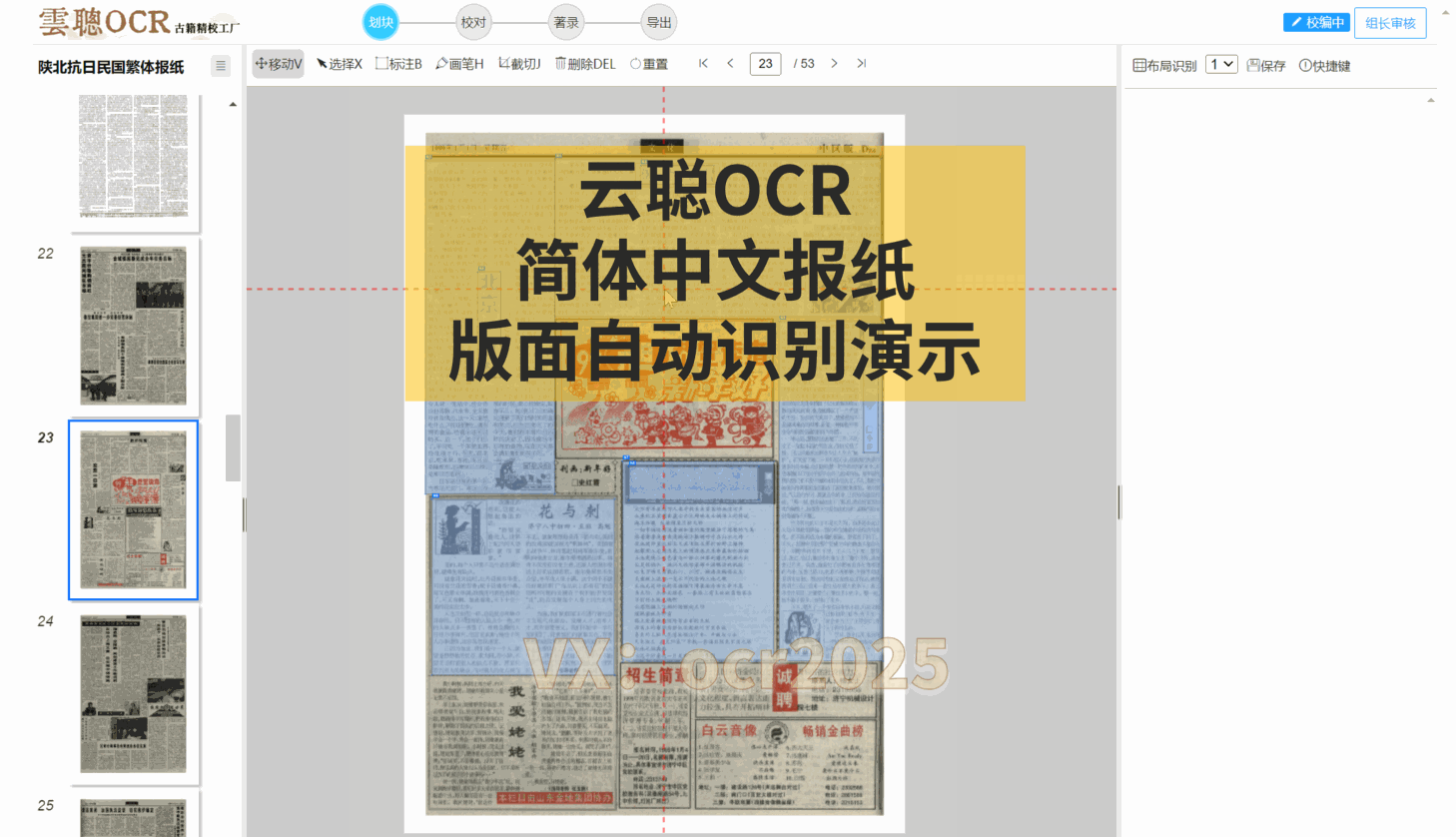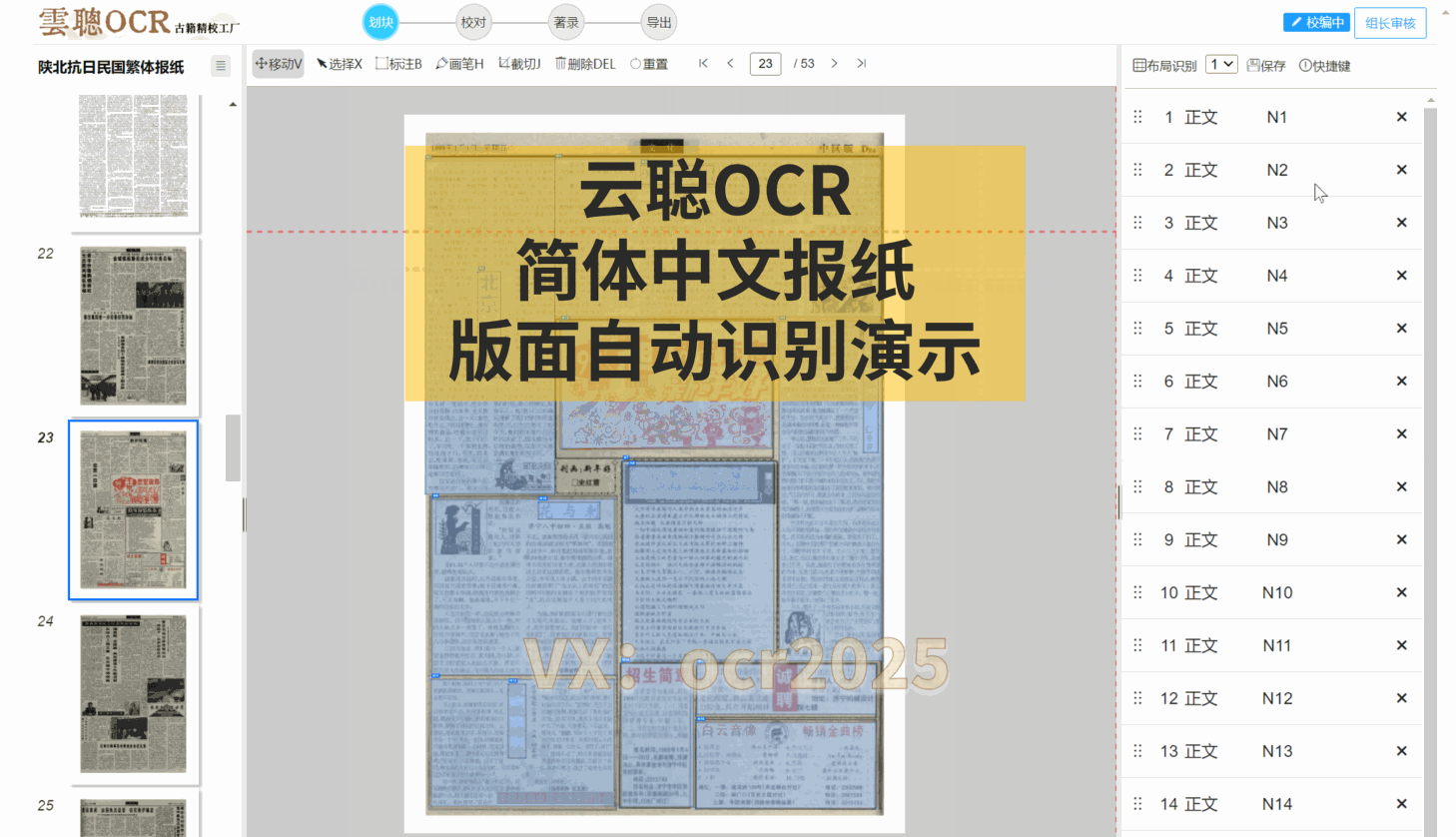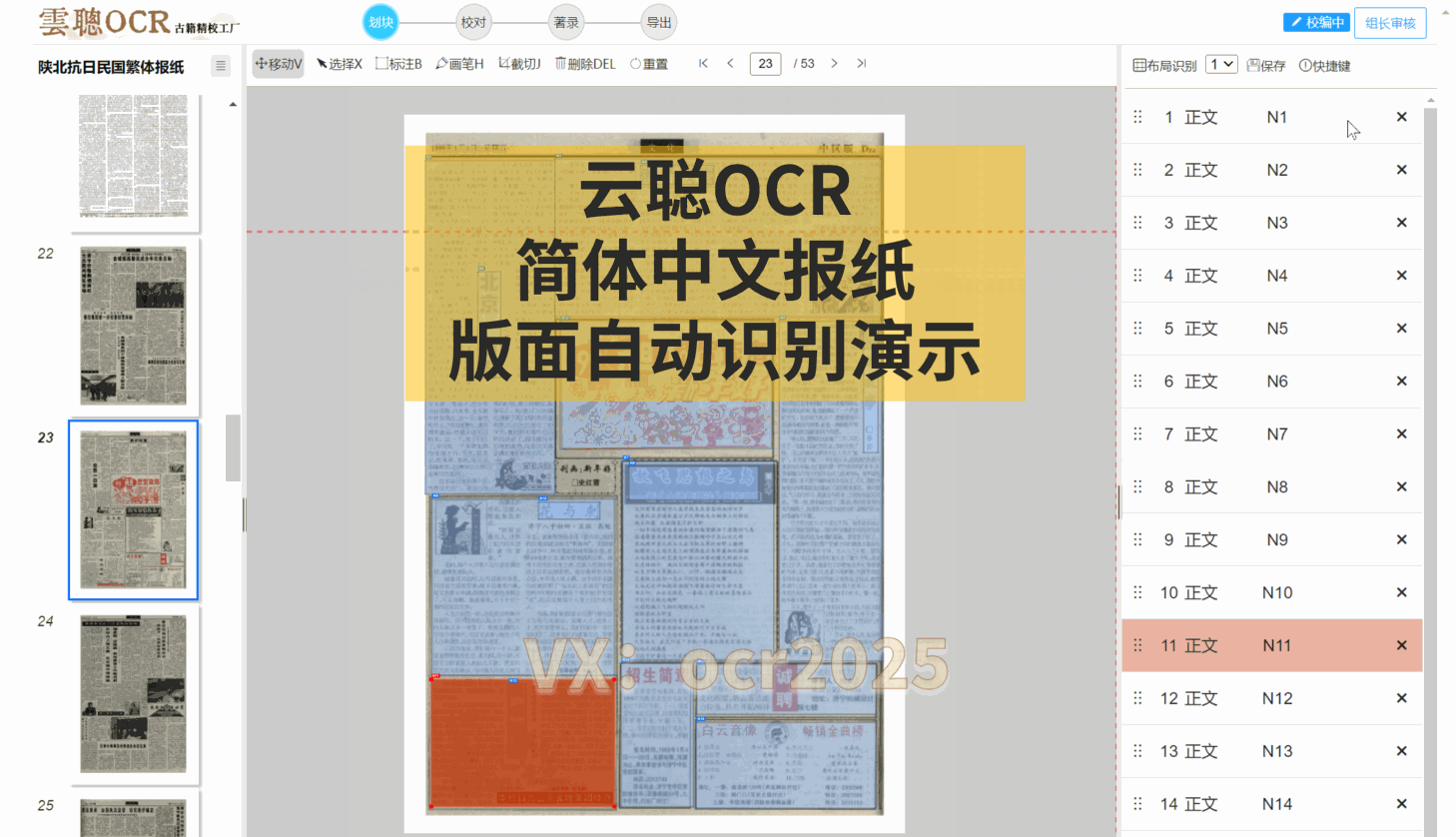
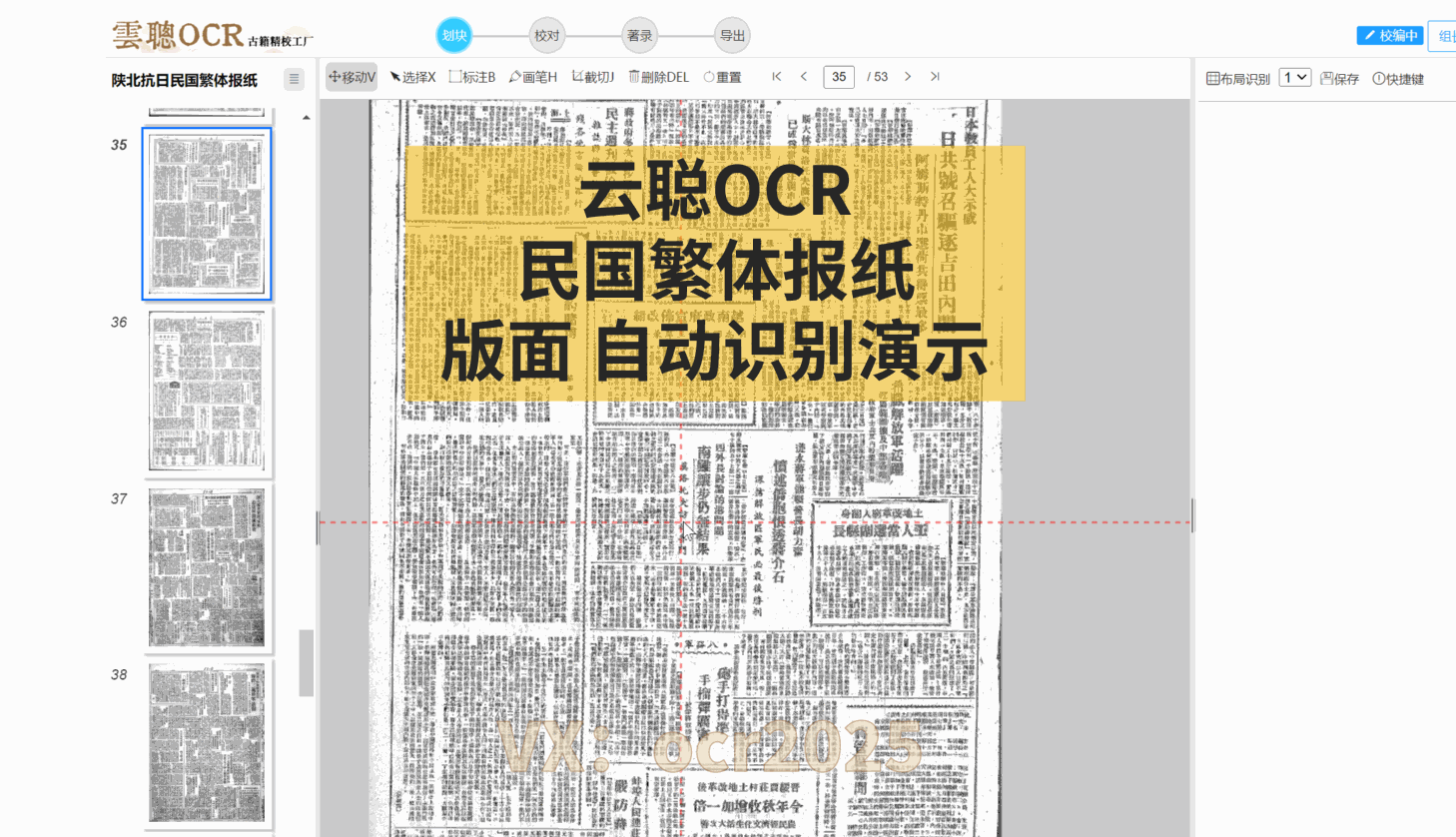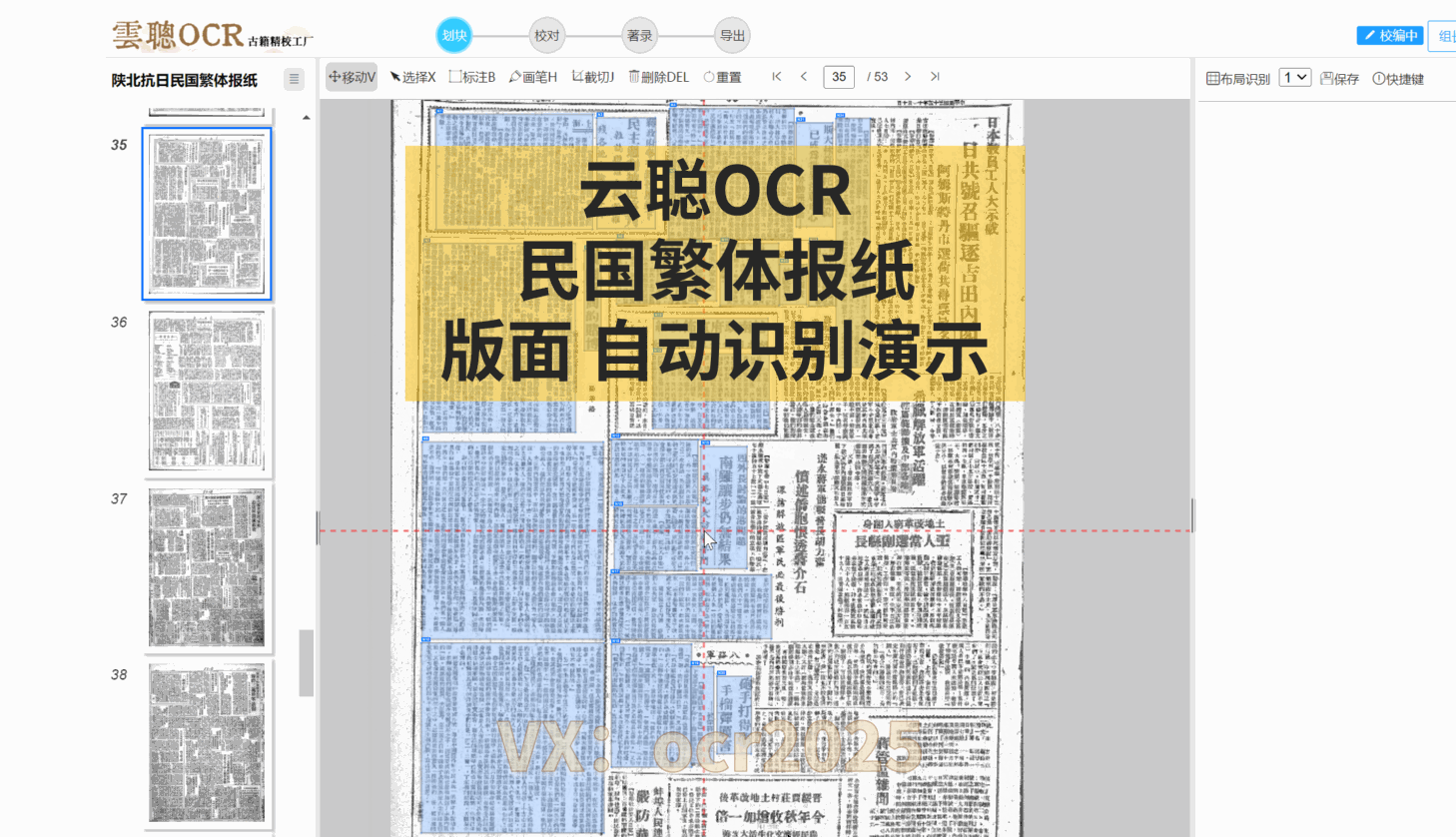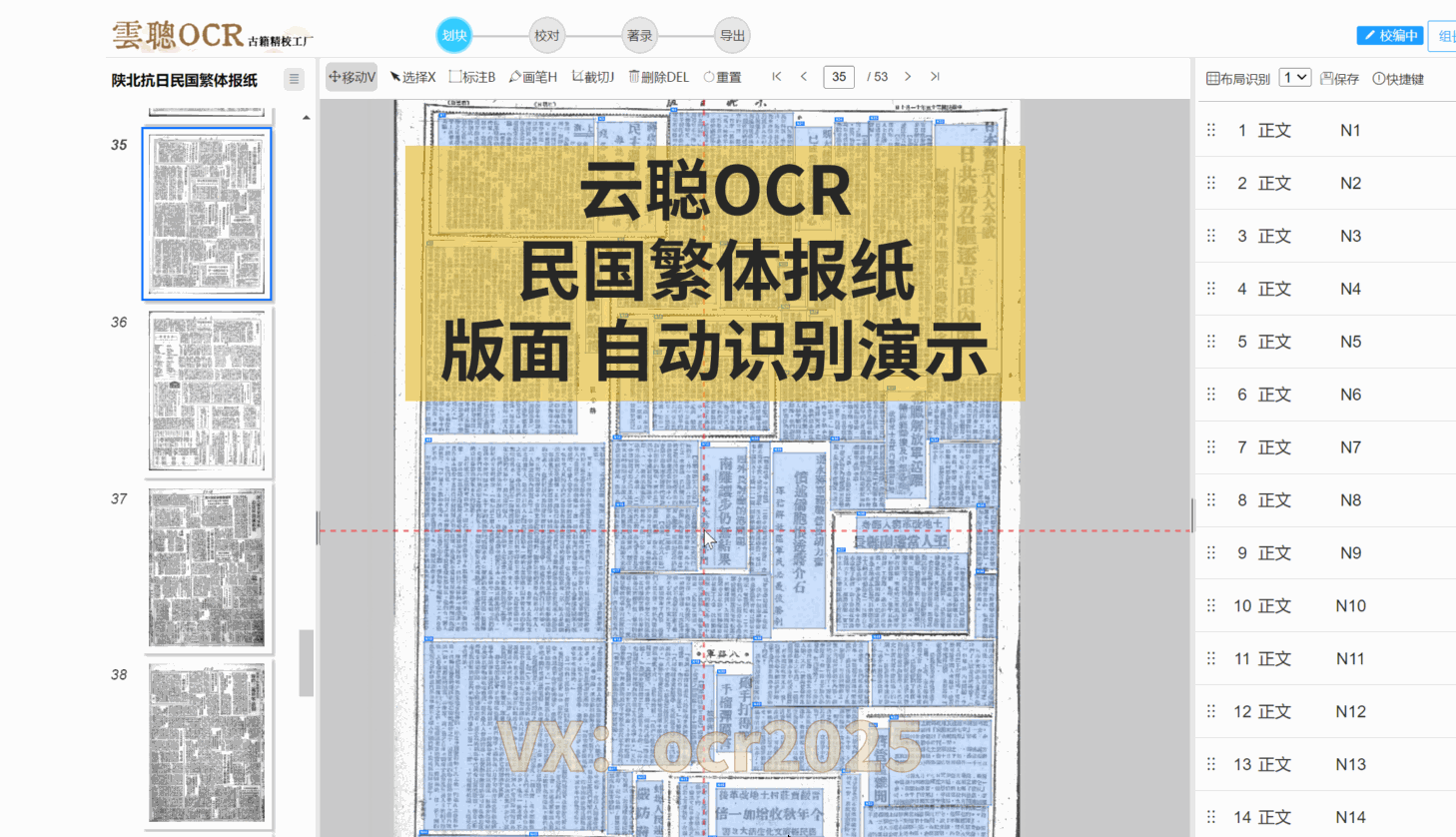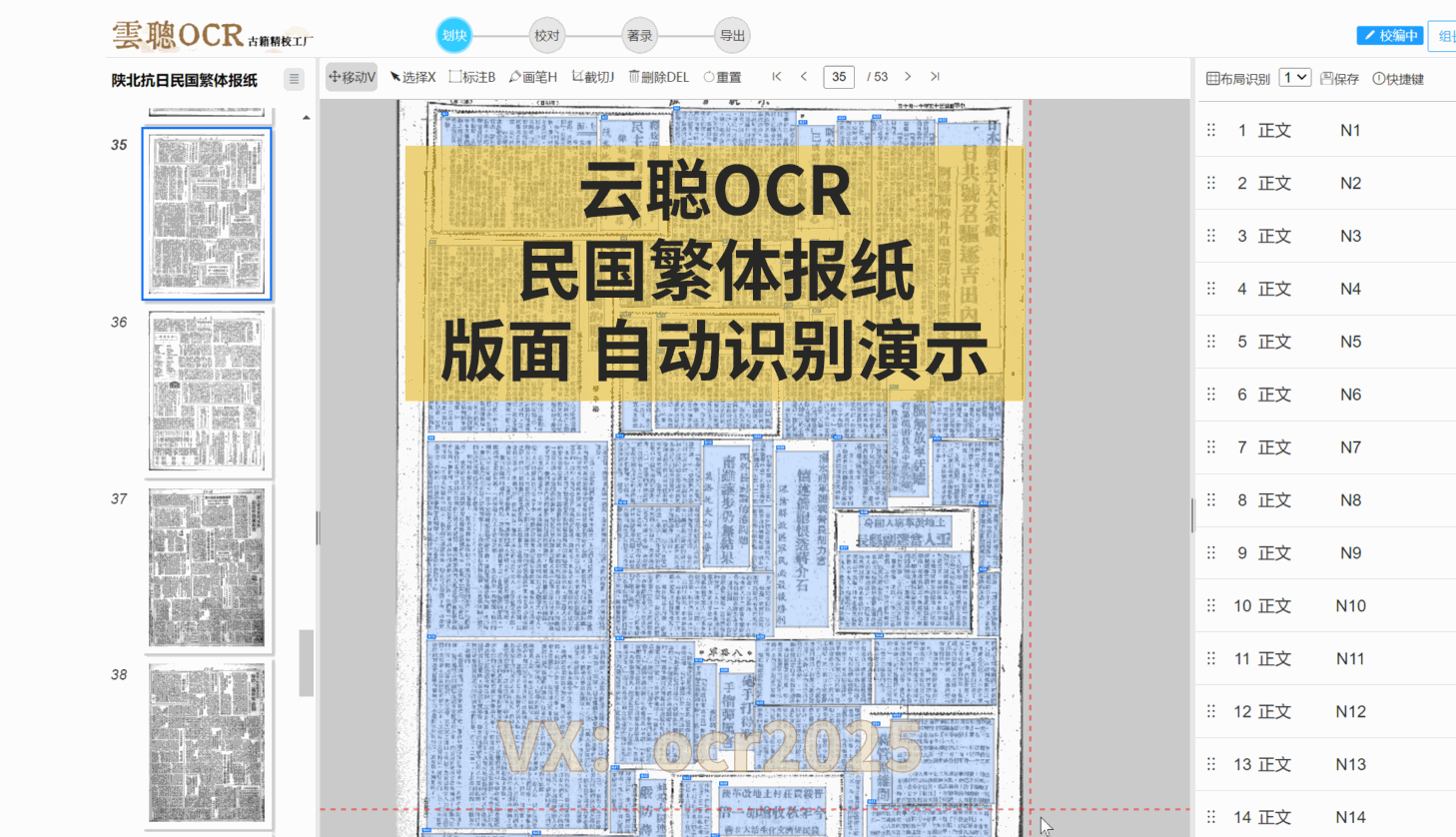
云聪OCR精校工厂的内置复杂版面识别引擎,对上下栏古籍、批注栏、竖版报纸以及简体中文报纸等各类版面,都能进行精准的版面分析。
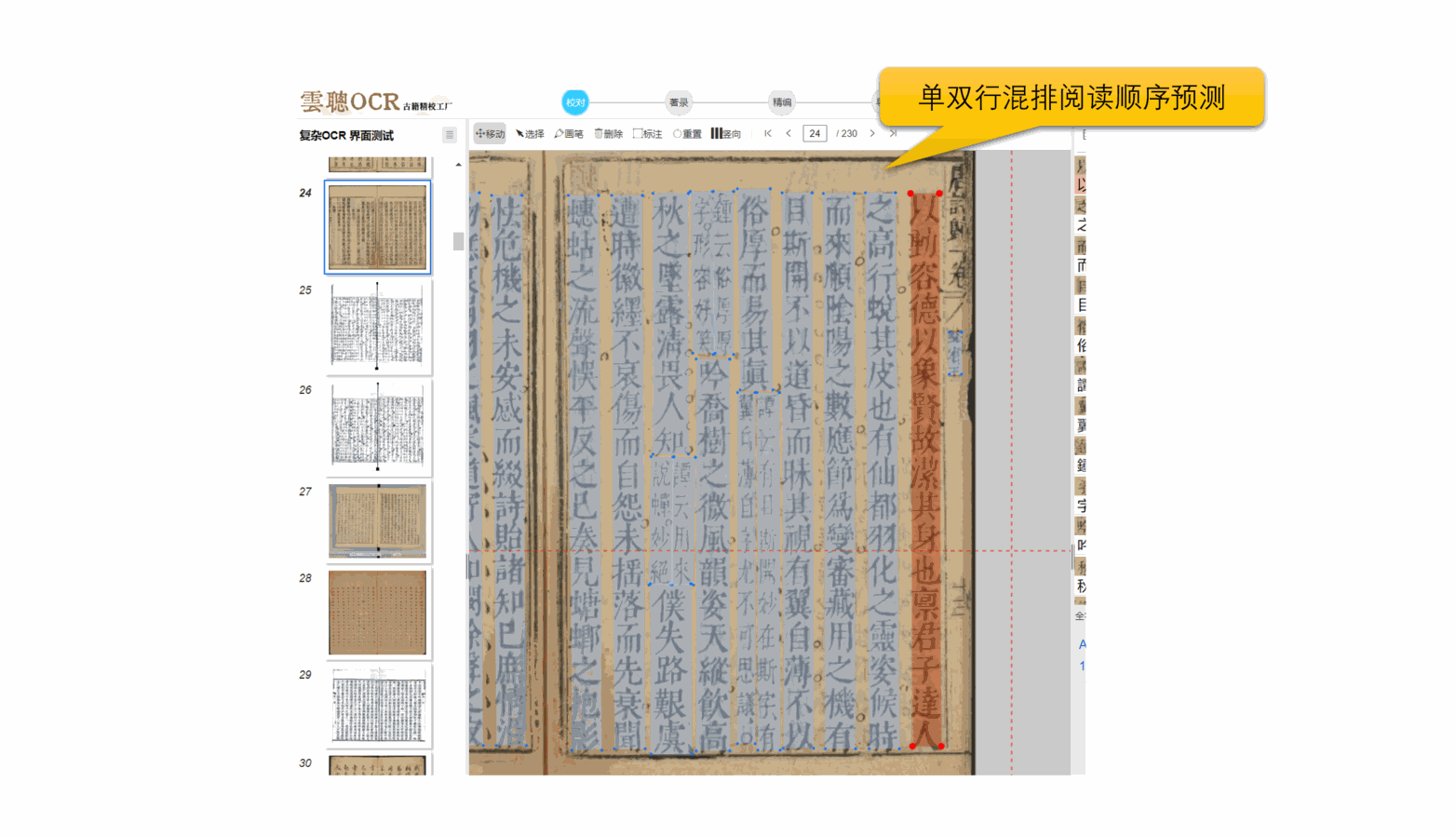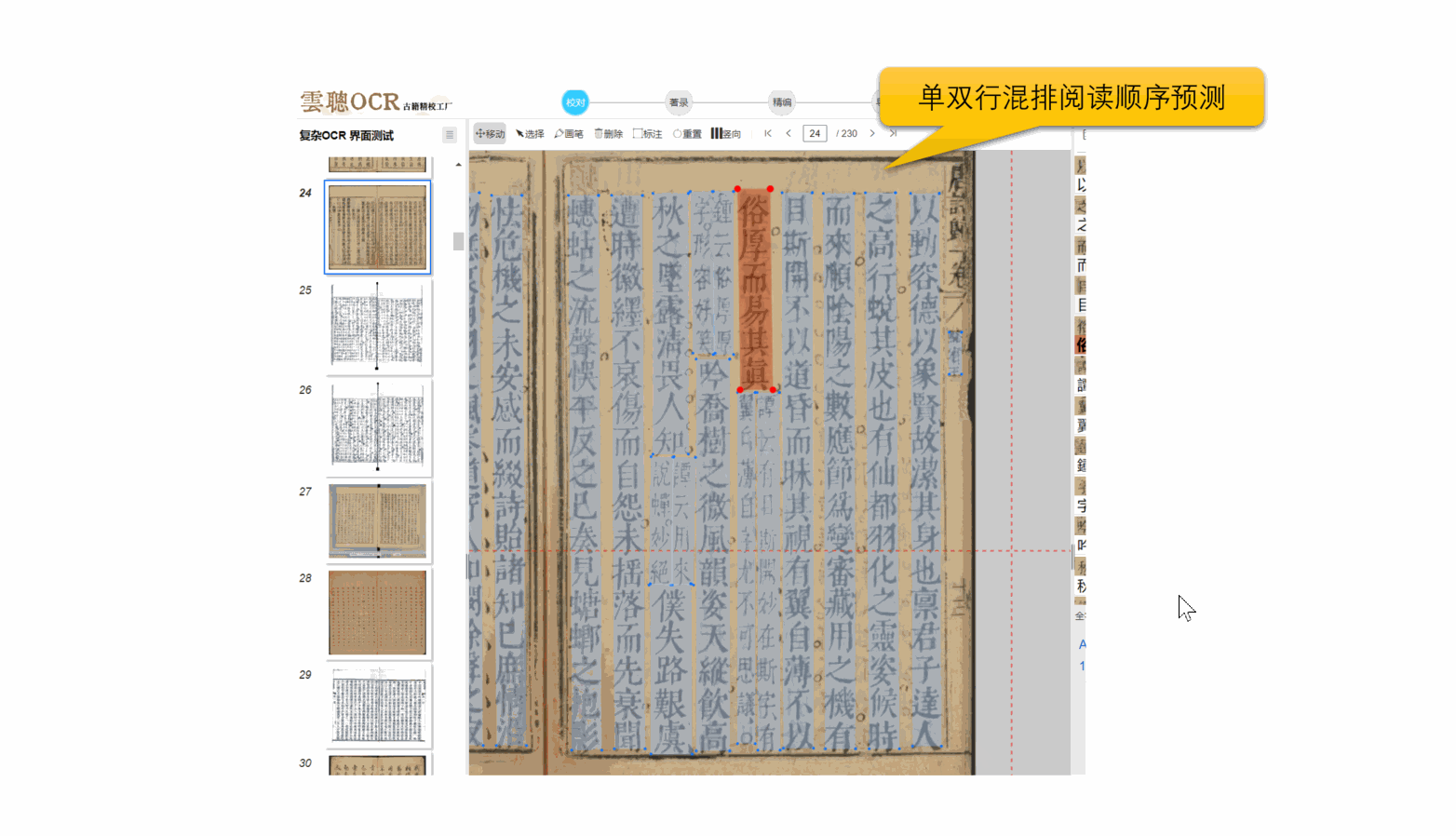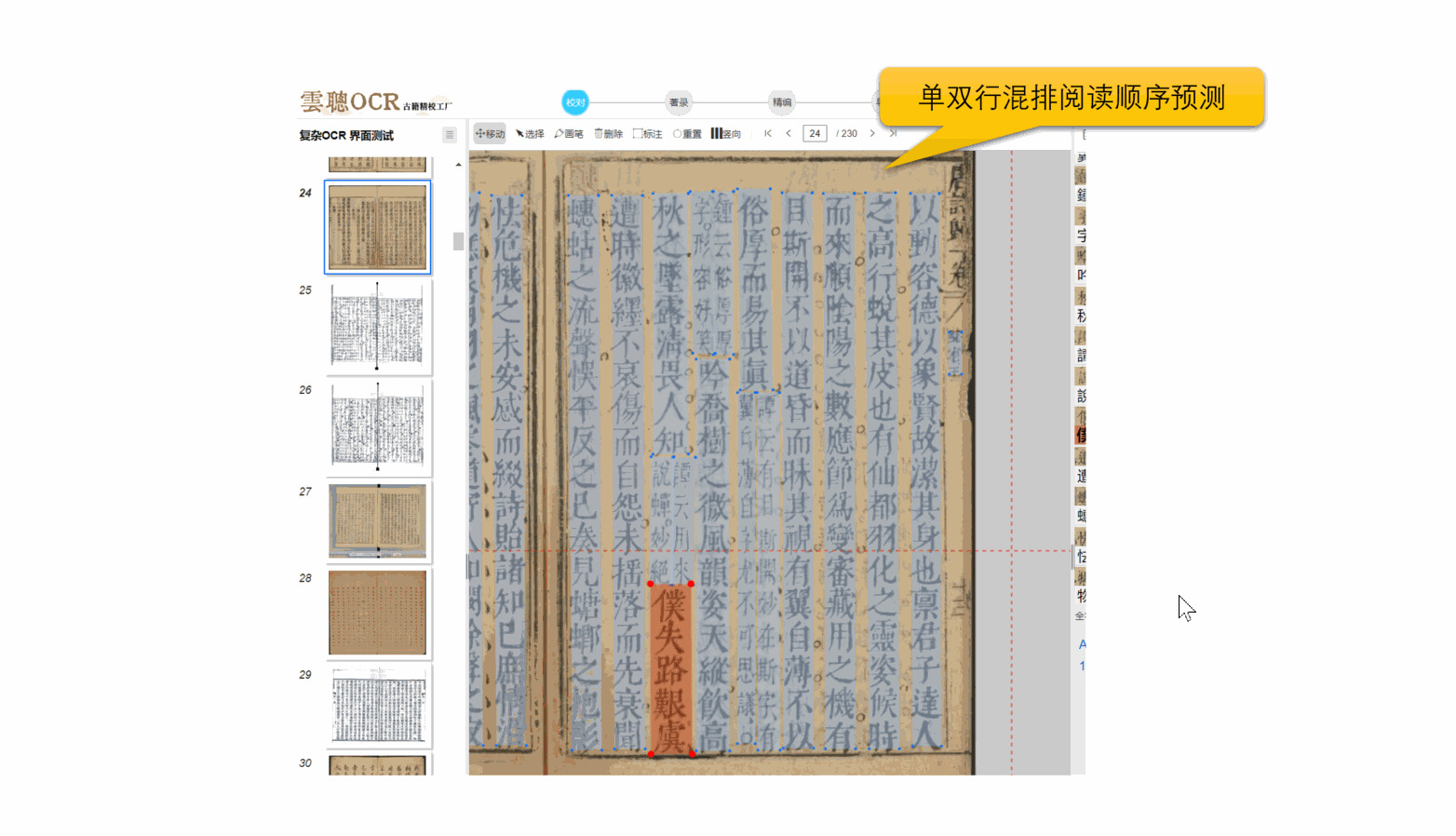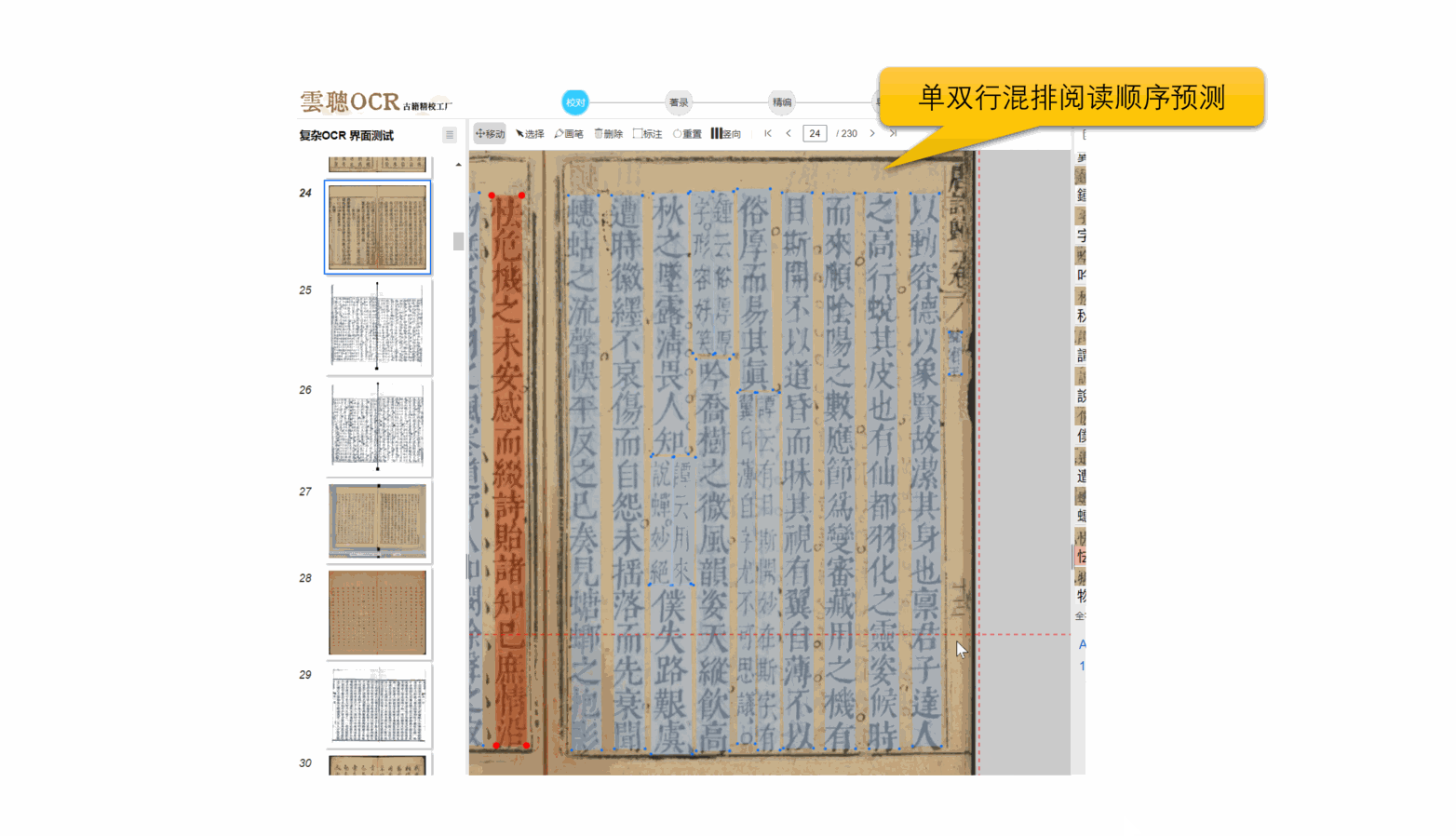
4、阅读顺序
云聪OCR精校工厂拥有强大的内置版面阅读顺序引擎,能够精准解析古籍筒子页、半筒子页、三栏稿本、上下栏古籍、批注栏等多种复杂格式。同时,对于竖版报纸和简体中文报纸等复杂版面,也能进行有效的阅读顺序分析。


5、集字校对
在云聪OCR精校企业版中,利用集字校对功能,多篇文档的相同字符图像得以集中展示,一目了然。这一功能大大减轻了校对人员的视觉负担,避免陷入繁琐的上下文判断,从而提高校对效率和准确性。

二、识别因素
云聪OCR的识别泛化能力能够适应大部分页面歪斜、透光、透字的情况,但是OCR识别效果好坏,关键看图像清晰度。简单来说,图像越清楚,OCR识别的准确率就越高。具体影响因素有:
1、分辨率:扫描时,图像的分辨率最好设置在DPI 300或以上,这样能保证OCR识别的效果。
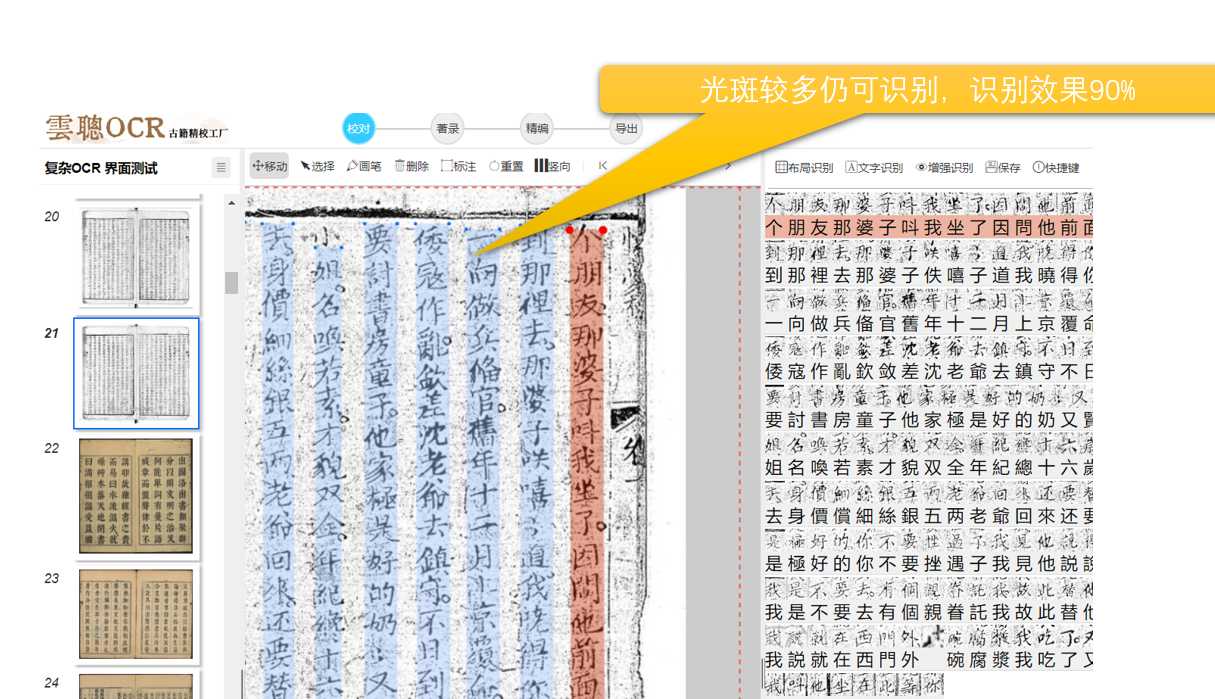
2、亮度、对比度:页面亮度、对比度要适中,太亮、太暗、光斑、阴影等都可能影响OCR的准确率。
3、颜色:平台可以识别全彩图、灰度图、黑白图等。一般来说,黑白图的识别效率更高,但如果处理不当,也可能导致识别错误。
4、页面歪斜:轻微的页面歪斜、扭曲、梯形失真,平台可以忽略,但文字倾斜超过10°时,识别错误率就会高。所以,如果图像页面有问题,建议先进行预处理。
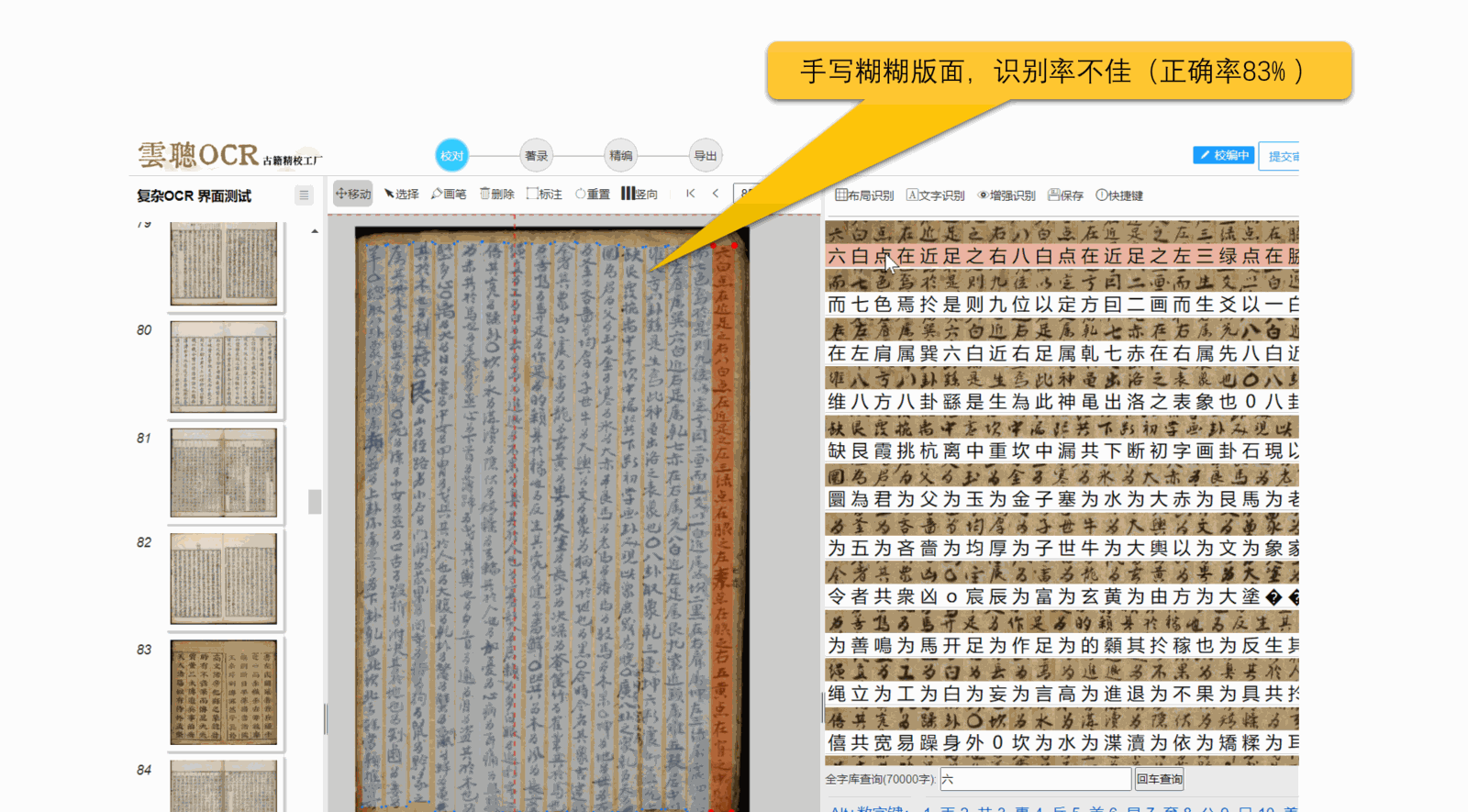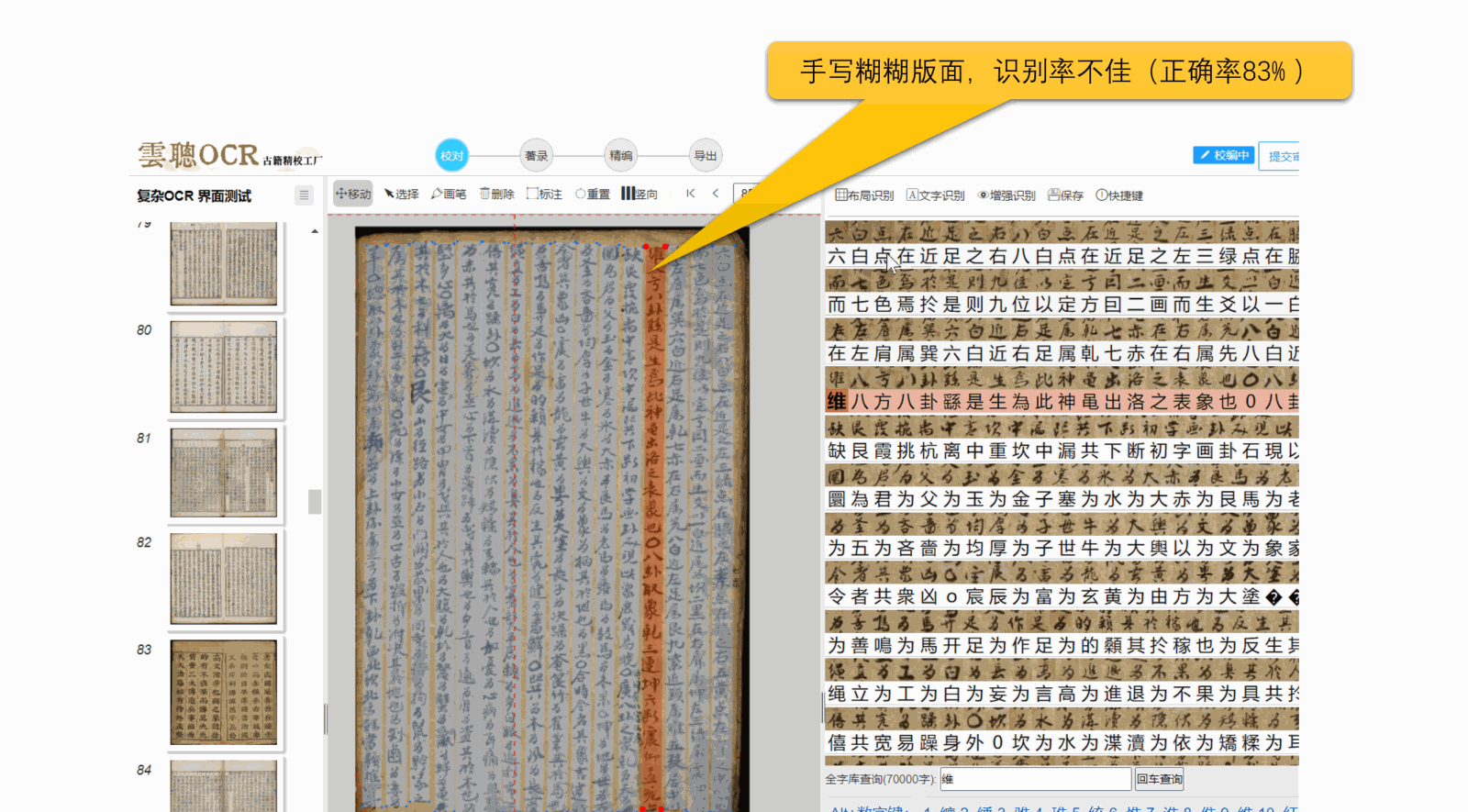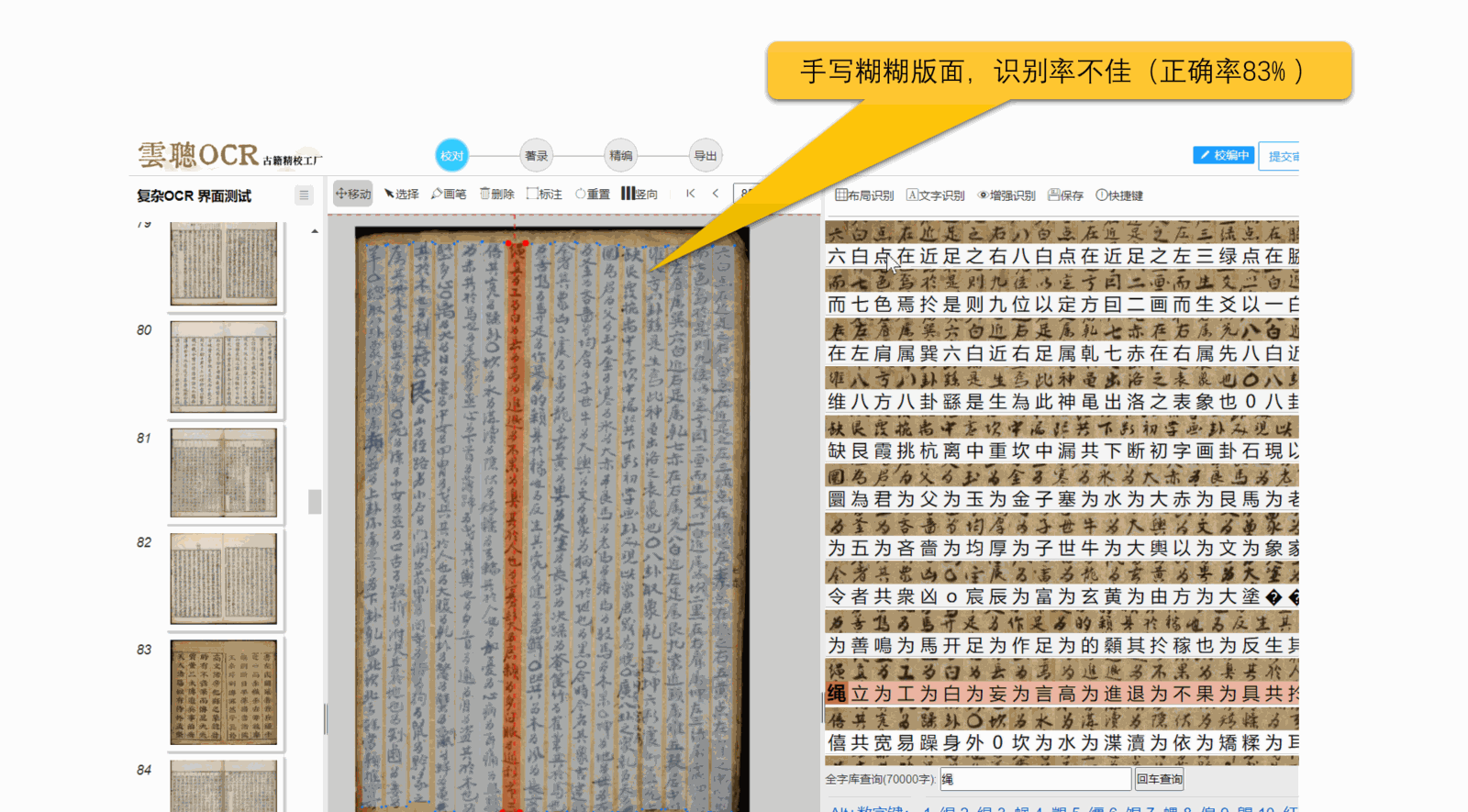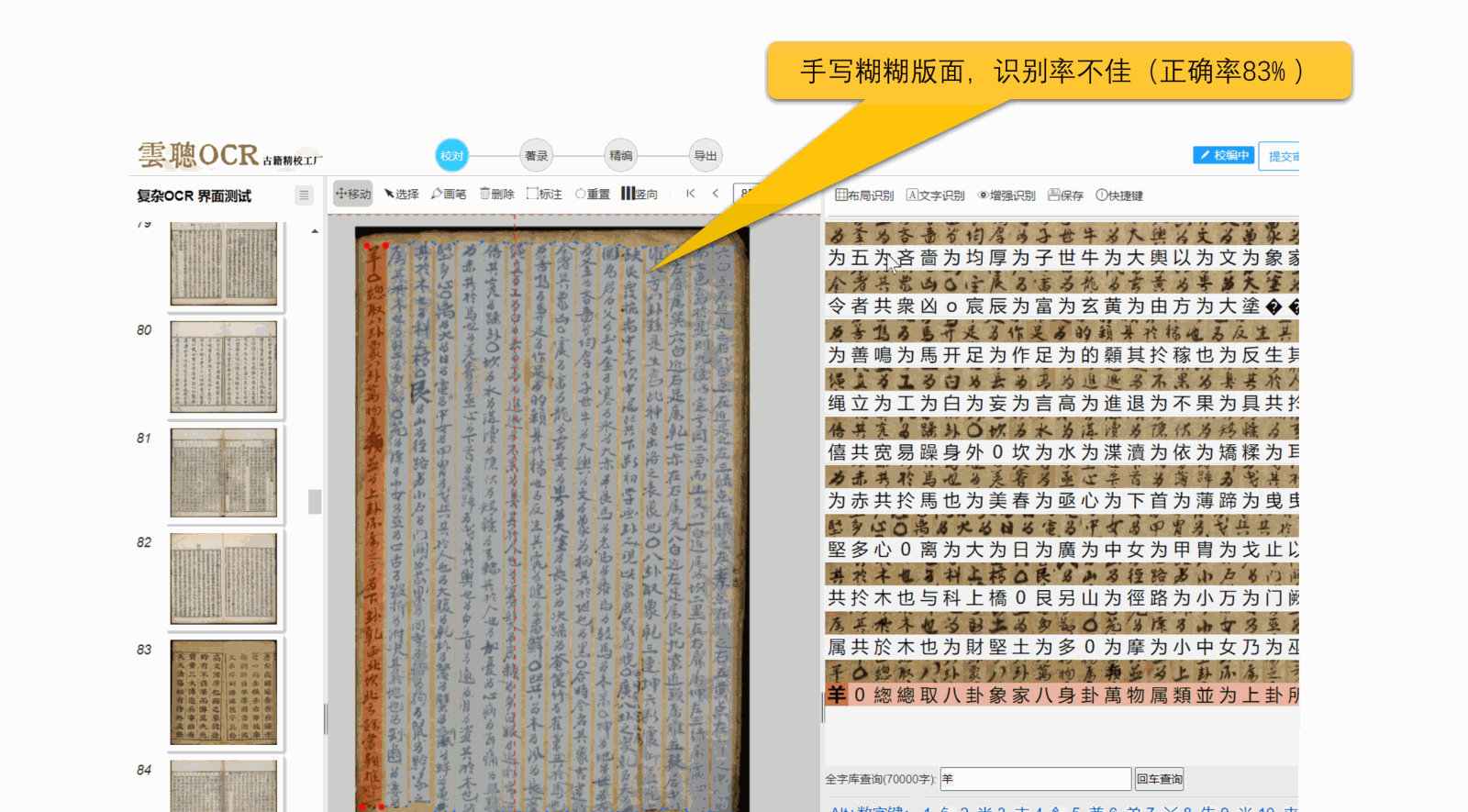
5、污损、模糊:页面上的透光、透字、彩点、黑边、污点等,都可能导致文字识别异常。
总之,清晰、标准的图像是OCR识别的关键。
三、布局分析
古籍智能整理平台主要服务对象是繁体竖排的古籍,包括筒子页和半个筒子页的图像。这些古籍的文本输出顺序是从右至左、从上到下。但平台也能处理其他类型的文献,如经卷、文书、卷轴等,只要它们的版面布局和古籍相似。
不过,对于一些特殊的页面布局,平台可能无法完美处理。比如:
1、当页面过长或过宽时(超过3000像素),可能会出现识别异常。
2、针对上下分栏的页面,系统会认为页面存在水平分隔线。
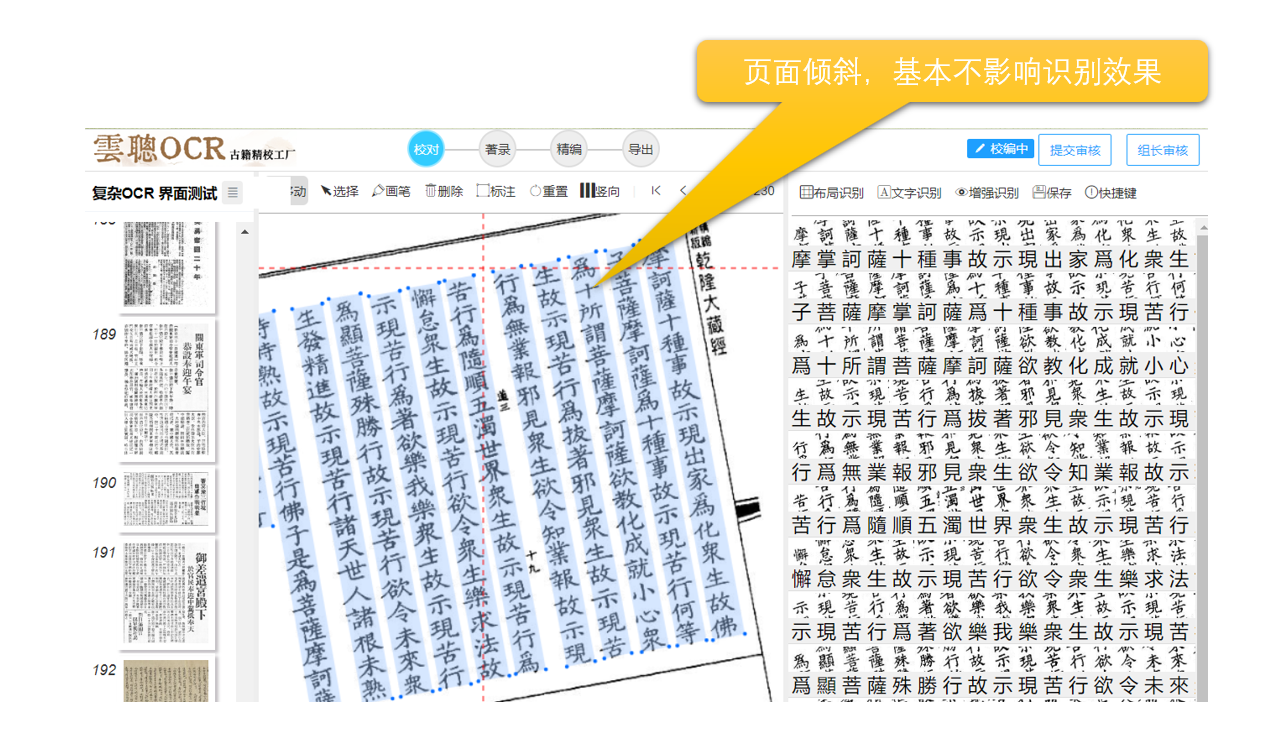
3、倾斜的页面在校编工作时有文字倾斜的情况,但不影响识别精度。
总的来说,要想获得更好的OCR效果,还是得保证图像的质量和版面布局的规范。
四、文字与字体
1、古文字
系统主要识别楷书、隶书,不支持甲金篆等古文字。
2、生僻字处理
系统针对GB18030-2022中文编码字符集中常见的47000个繁体字体有较好的识别能力。其他40000个左右使用率极低的生僻字,系统暂时未做优化处理。如果需要处理这些生僻字,可以使用系统提供的全字库字符查询工具来帮助你录入。
3、符号与非汉字字符
虽然系统可以识别常见的句号、逗号,但对于现代新式标点、空格、书名号等,以及其他的非汉字语言文字,暂时还无法识别。
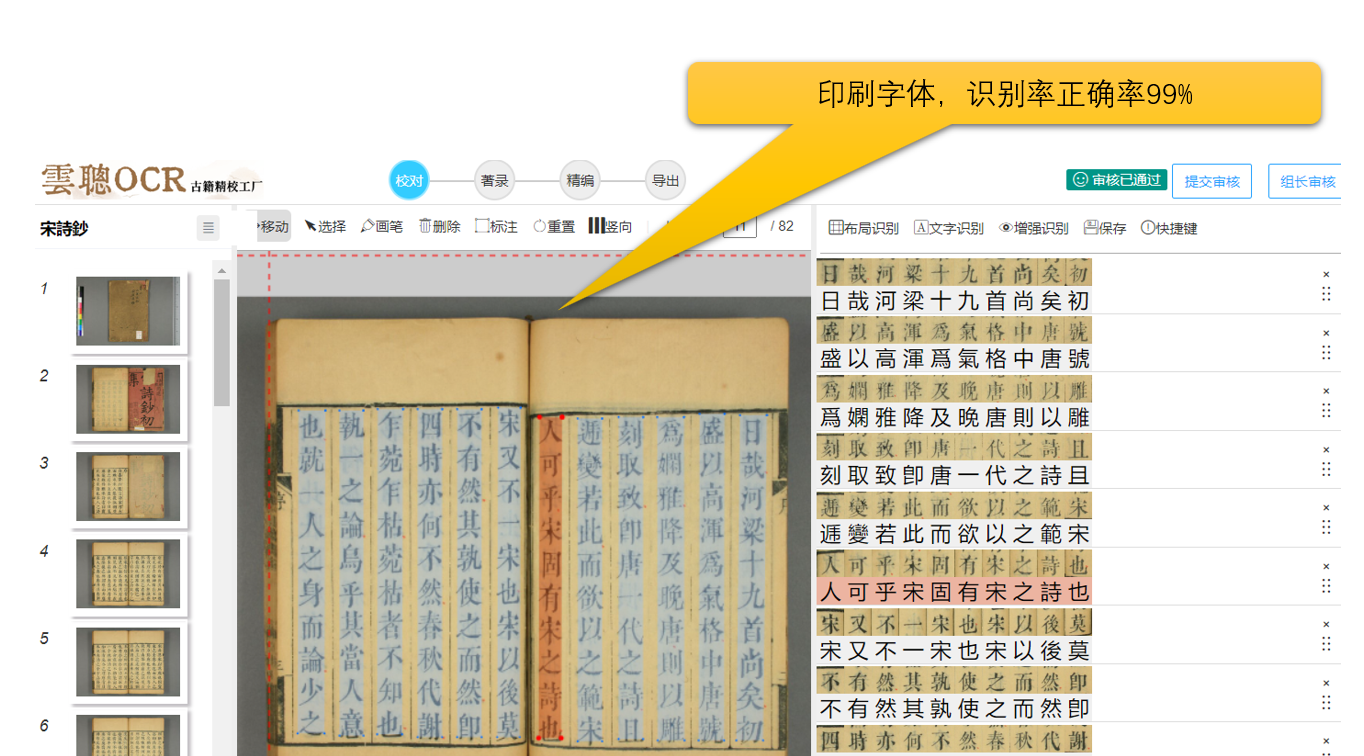
4、印刷字体
系统对明清的方体字(也称硬体字、匠体字、宋体字)、宋元以来的软字体,如颜体、欧体、柳体、赵体等均有较好的识别效果;对标准楷体写刻本和名家手写上板的精刻本等,也有良好的泛化能力。一般来说,笔画清晰、字形厚重的字体识别效果好;而笔画细、连笔多的字体效果较差。
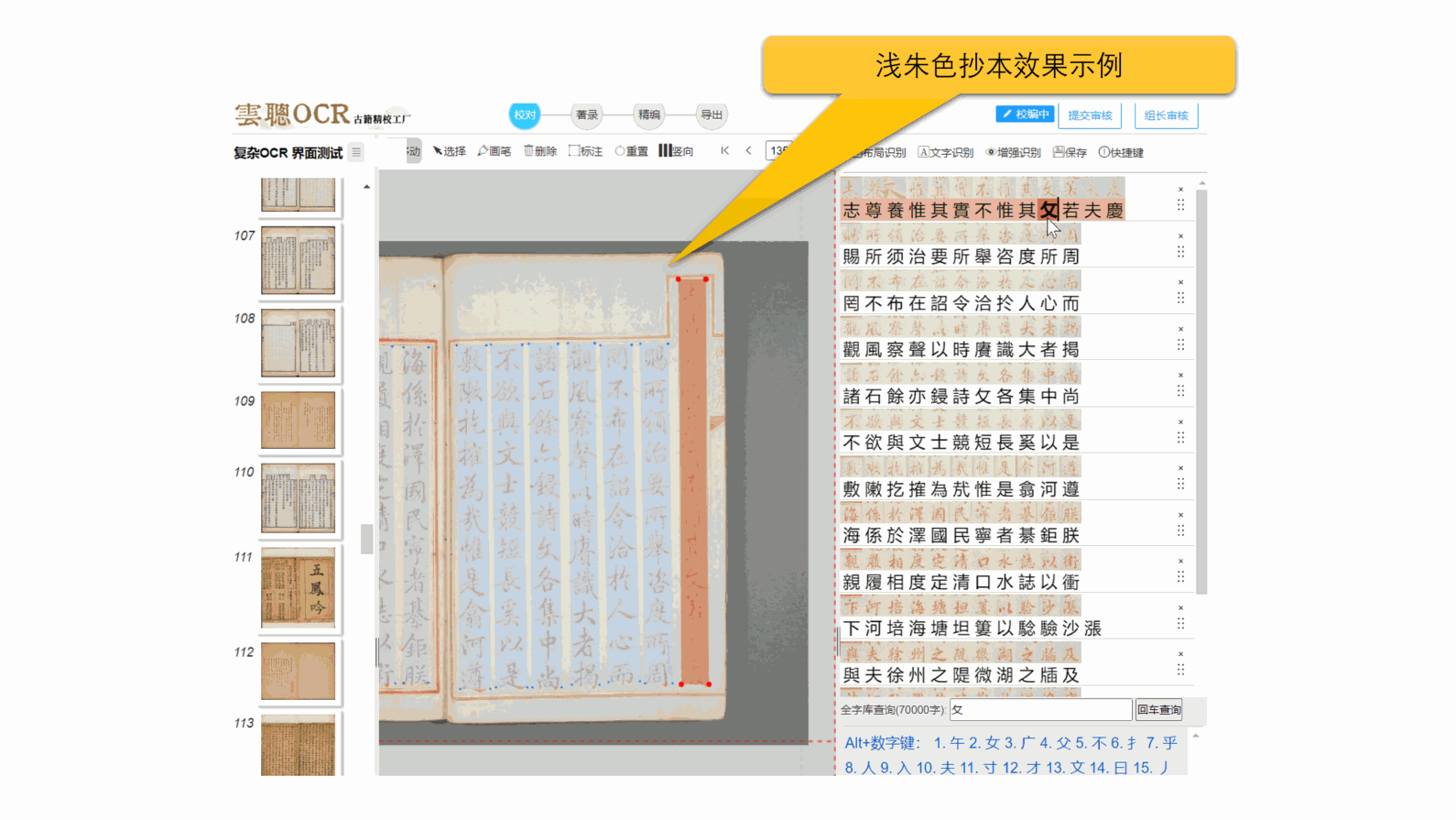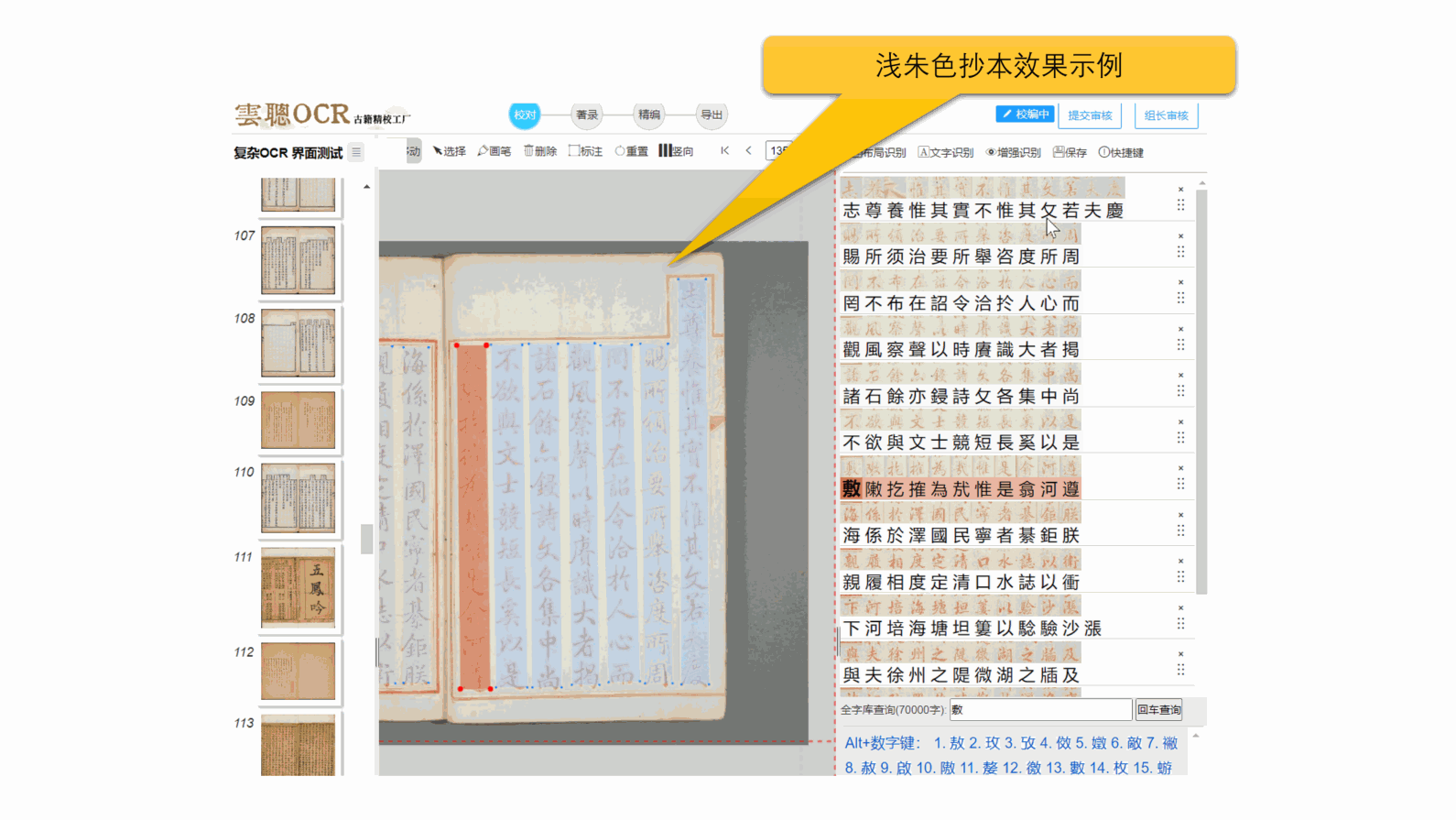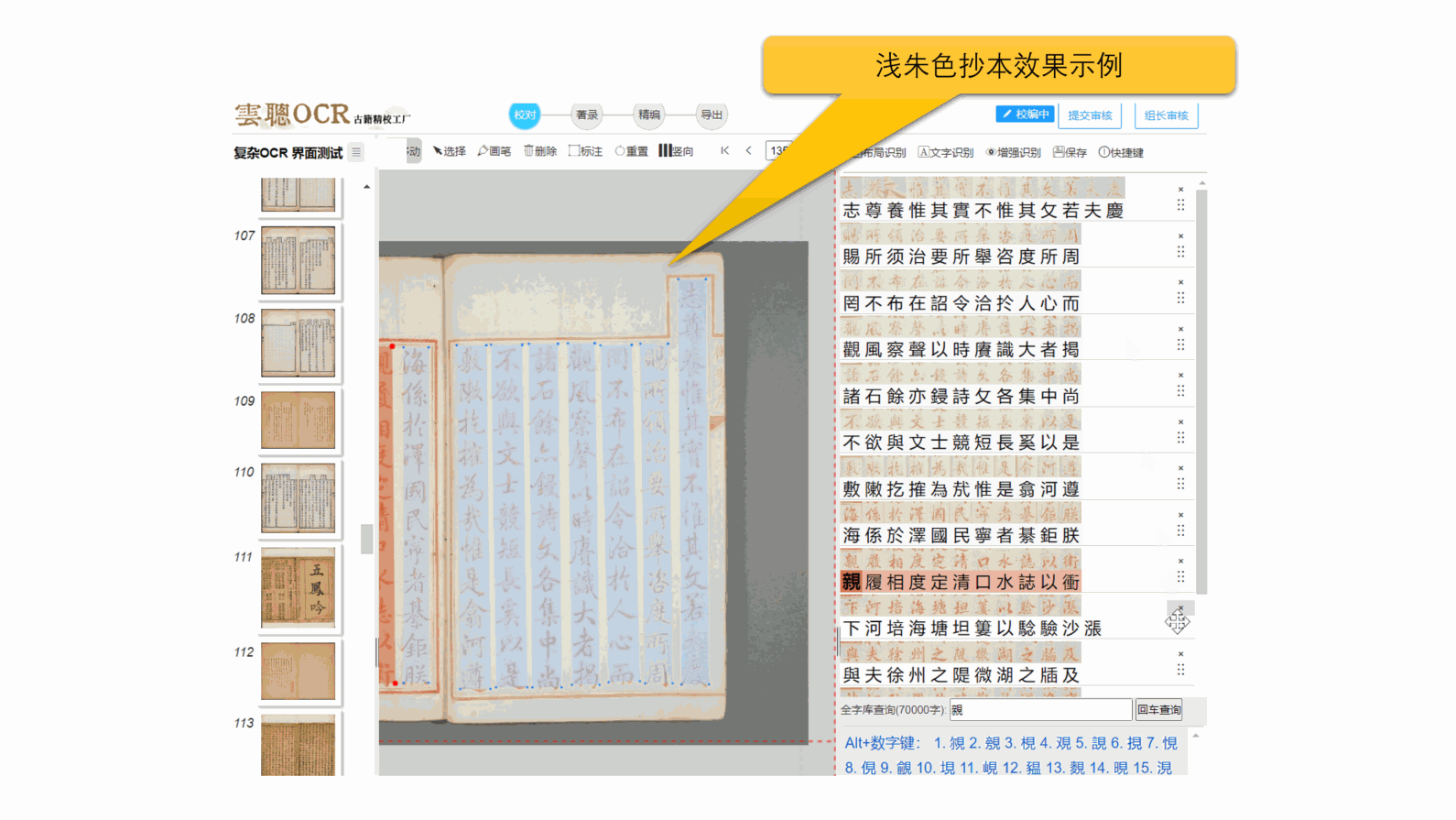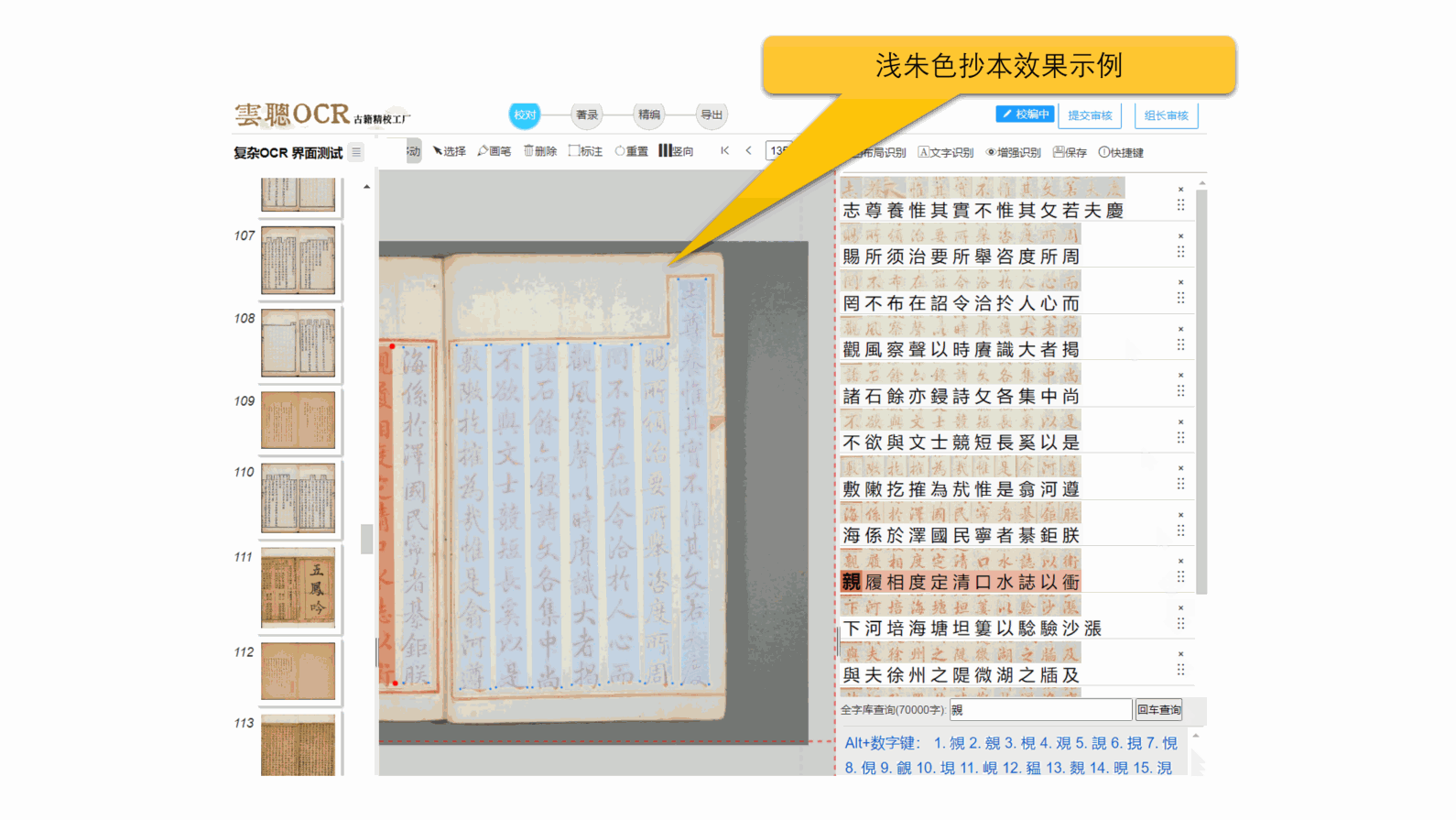
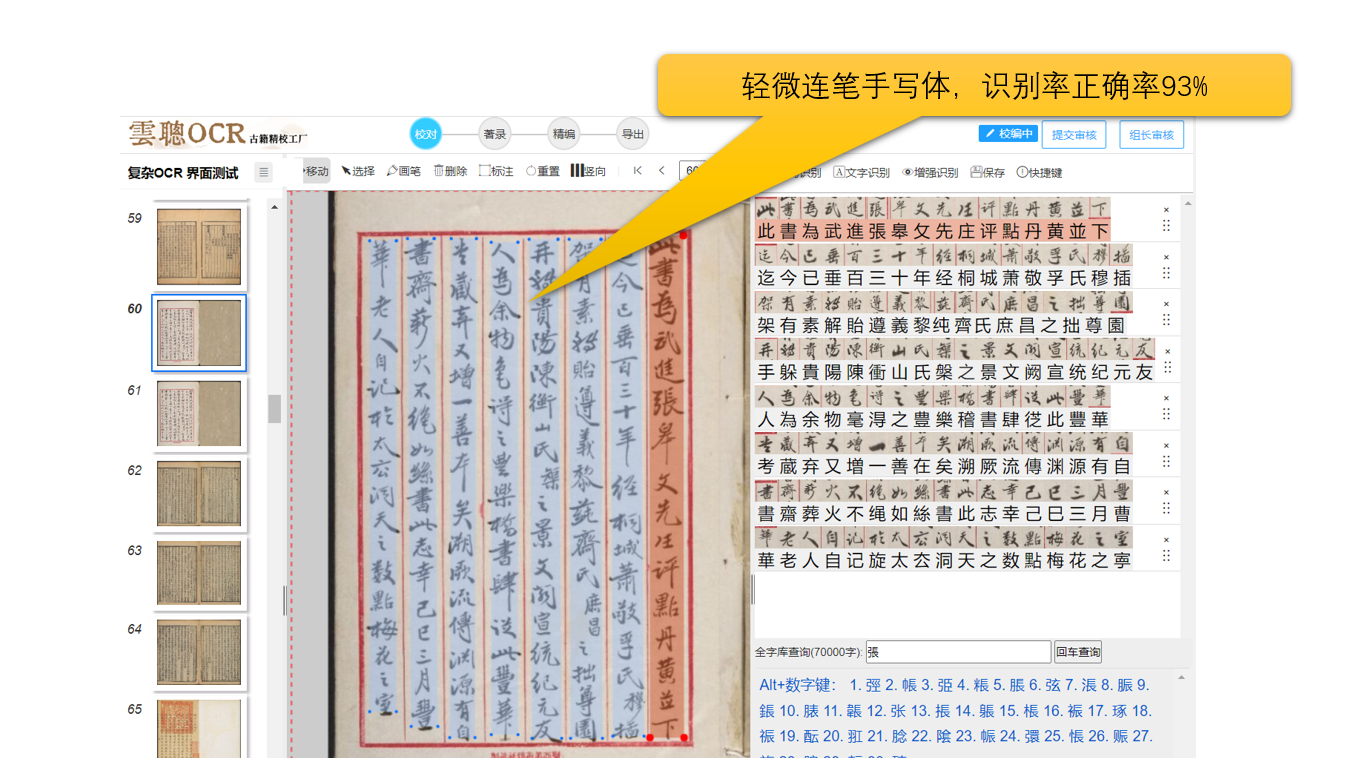
5、手写字体
系统对以楷宋体书写的写本、稿本、抄本有较好的适应性。但对于行书、草书风格文字,识别效果可达90%以上。
五、其他元素
1、批校
天头位置整齐的批校,系统可以单独处理,不会影响正文的顺序。但行间整齐的批校可能会被当作普通文字行。而那些挖改、涂改、勾乙则会对识别结果产生较大影响。
2、注释
对于古籍中的小字注释,系统有较好的处理能力。但如果是连续的多行小字或更小的注释,因为大小差异不明显,可能会被误识别为普通的双行小注。
3、表格
目前的系统对于表格的处理能力还不够强大。如果表格的栏线不明显,或者与文字靠得太近,以及模糊的行列关系和合并的单元格,都可能导致表格识别效果不佳。
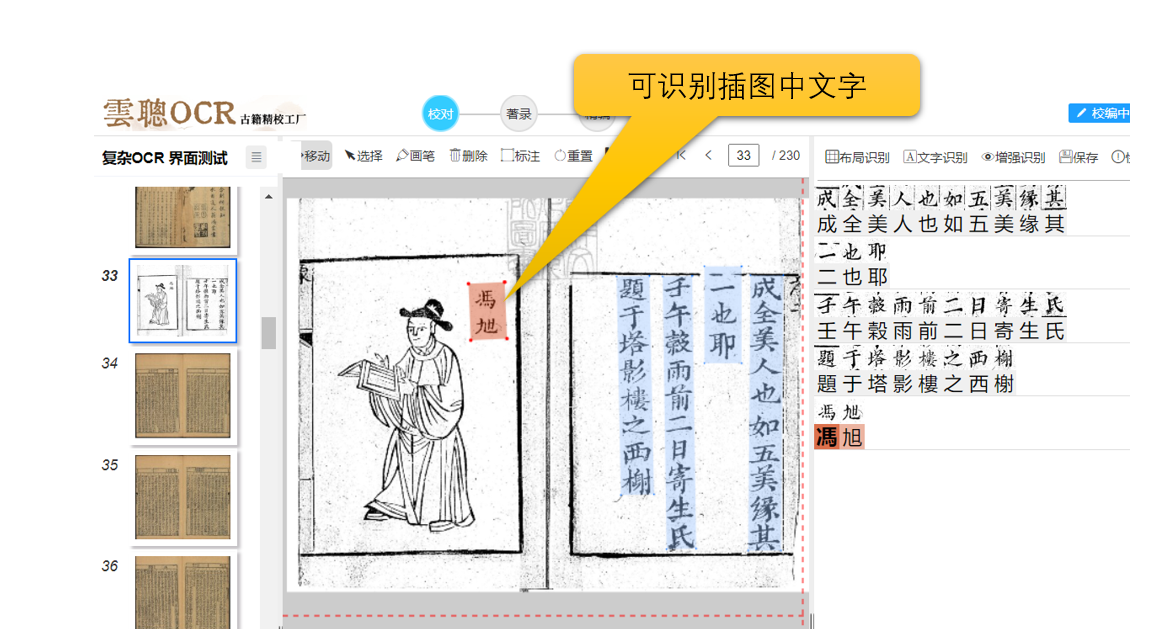
4、插图
有时候,页面中的插图可能会被误识别为文字。同样,插图里的文字如果和线条混在一起,就很容易被识别错误或者遗漏。